Implementation Guide
0 mins to read
MyGeotab API Adapter Data Optimizer — Solution and Implementation Guide
Implementation Guide
0 mins to read
The MyGeotab API Adapter uses data feeds to pull the most common data sets from a MyGeotab database and stream the data into tables within a supported relational database.
Solution and Implementation Guide
Latest Update: 2024-04-23
Revision History
Refer to the Change Log section for information about changes to the MyGeotab API Adapter solution and this document.
Introduction
! IMPORTANT: The Data Optimizer adds capabilities to the MyGeotab API Adapter. It is necessary to deploy and configure the MyGeotab API Adapter as a prerequisite to deploying and configuring the Data Optimizer. This document provides supplemental information specific to the Data Optimizer. For detailed information about the MyGeotab API Adapter solution along with instructions related to its deployment, please refer to the MyGeotab API Adapter - Solution and Implementation Guide.
The MyGeotab API Adapter uses data feeds to pull the most common data sets from a MyGeotab database and stream the data into tables within a supported relational database. As detailed in the Database Maintenance section of the main guide, the adapter database has been designed as a staging database, serving as an intermediary between the Geotab platform and the final repository where the extracted data will ultimately be stored for further processing and consumption by downstream applications.
The Data Optimizer takes the adapter solution to the next level, following the Suggested Strategy outlined in the main guide. It migrates data from the adapter database into an “optimizer database” which can then be queried directly by applications. Additional services are included to enhance the data and overcome certain challenges such as linking data points with different timestamps from different tables. For example, the StatusData and FaultData tables have added Latitude, Longitude, Speed, Bearing and Direction columns that can optionally be populated using LogRecords and interpolation techniques.
This document provides supplemental information specific to the Data Optimizer. For detailed information about the MyGeotab API Adapter solution along with instructions related to its deployment, please refer to the MyGeotab API Adapter - Solution and Implementation Guide.
✱ NOTE: At this time, SQL Server is the only supported database type for the optimizer database. While multiple database types are supported for the adapter database, if all tables are to be included in a single physical database, it will need to be SQL Server. It is, however, possible to use different types of databases for the adapter and optimizer. For example, the adapter database could be PostgreSQL while the optimizer database is SQL Server. At some point in the future, support may be added for additional database types.
✱ NOTE: At this time, the Data Optimizer is limited in scope and the optimizer database contains a limited number of tables. Additional capabilities and tables will be added incrementally over time until the optimizer database eventually includes tables to warehouse all data from the adapter database. The intention of this approach is to make capabilities available as soon as possible rather than forcing everyone to wait for an extended period for a “complete” solution to be ready.
Quick Start Guide
This section provides a quick summary of the steps required to download and deploy the Data Optimizer component of the MyGeotab API Adapter. While it is no substitute for all of the detail provided in this guide, the most important steps are highlighted and this section may serve as a high-level deployment checklist.
Quick Start: Download and Deploy the Data Optimizer
✱ NOTE: The steps outlined below are for one of several possible ways the solution can be deployed. Information relating to other deployment possibilities can be found throughout this guide. For instance, the Data Optimizer can
- be deployed to various operating systems (Windows and Linux-based packages are included with each release published to GitHub); and
- be modified to include new or altered capabilities.
The steps to download and deploy the latest release of the Data Optimizer in a Windows-based environment with SQL Server as the database, assuming that separate databases are used for the adapter and optimizer and that all optimizer services are installed on a single machine only, are as follows:
1 | Ensure that the main MyGeotab API Adapter application and database is first downloaded and deployed. Refer to the Quick Start: Download and Deploy the MyGeotab API Adapter section of the main guide for details. |
2 | Download the latest release of the MyGeotab API Adapter from GitHub (i.e. following Steps 1-3 in the Using Published Release from GitHub section). The Data Optimizer files to download are:
Once downloaded, extract the contents of the zip files. |
3 | Setup the optimizer database (following Steps 1-4 in the SQL Server database setup section):
|
4 | Configure and deploy the Data Optimizer application (following Steps 1-4 in the Application Deployment and Configuration section):
✱ NOTE: In a production environment, it is best to setup a process to run the optimizer using a system account. On a Windows Server, for example, Windows Task Scheduler can be used to create a task that runs MyGeotabAPIAdapter.DataOptimizer.exe on server startup. |
Solution Information
This section provides supplemental information related to the Data Optimizer. It provides detailed information about the architecture, logic and data models of the solution. Usage and deployment-related instructions can be found in the Solution Usage and Implementation section of this guide.
Solution Architecture
The following diagram provides an overview of the Data Optimizer architecture integrated within the overall MyGeotab API Adapter solution.
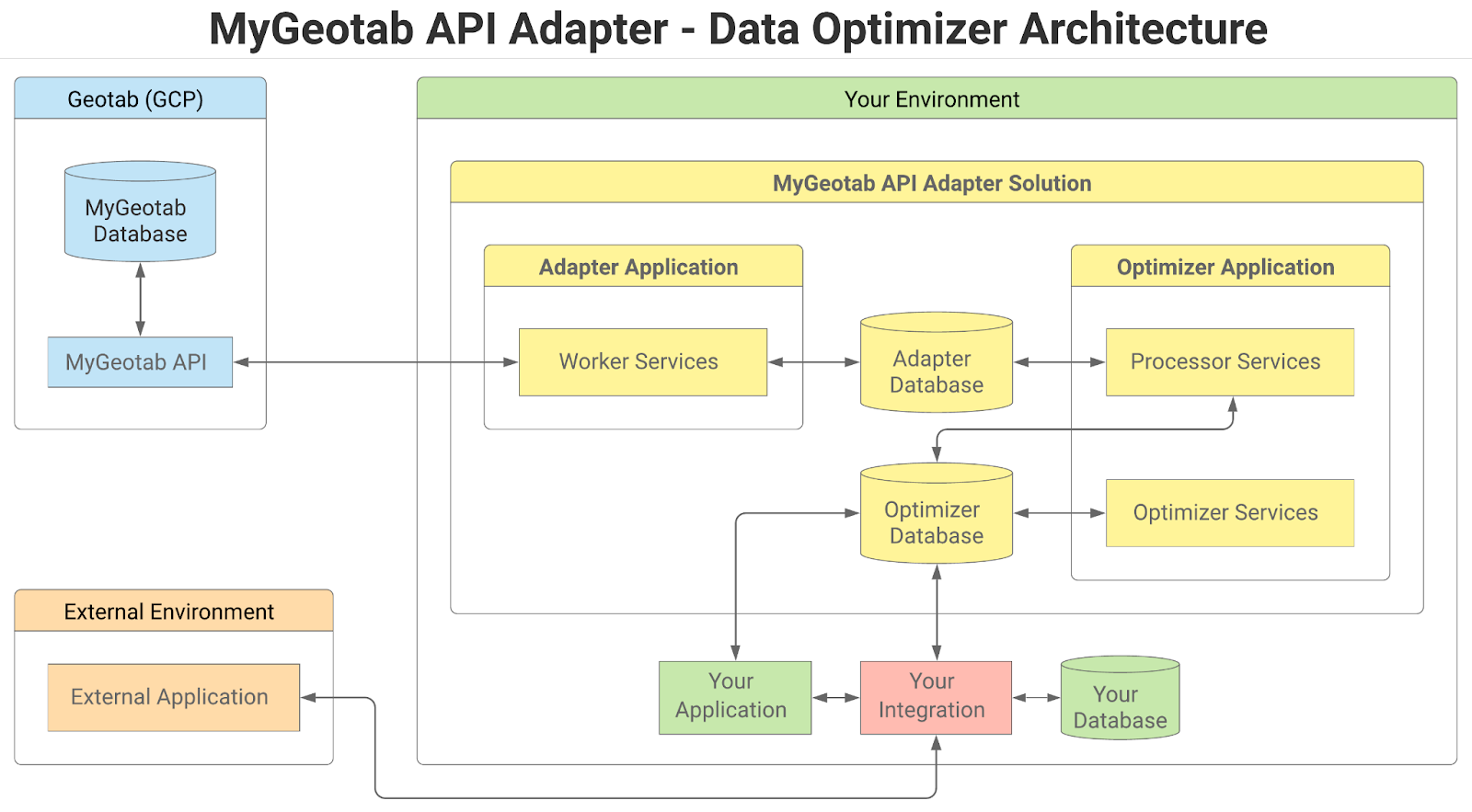
Within the context of the overall solution, the adapter application includes a number of services that primarily extract data from a MyGeotab database via the MyGeotab API and write the data to tables in the adapter database. Although it is included within the same Visual Studio solution as the MyGeotab API Adapter, the Data Optimizer is a separate application consisting of two types of services - processors and optimizers - and an optimizer database.
Optimizer Database
The optimizer database contains tables similar to the adapter database, but with added indexes to facilitate creation of custom views and direct querying by applications and/or integrations. Additionally, some of the tables contain extra value-added columns that can optionally be populated by the optimizer services. Although entitled the “optimizer database”, the tables all have slightly different names than their “adapter database” counterparts and both sets of tables can technically be included in the same physical database, if desired.
Processors
Processor services iteratively move batches of data from tables in the adapter database to their counterpart tables in the optimizer database. Once a batch of records has been successfully written to an optimizer database table, they are deleted from the corresponding table in the adapter database.
Optimizers
Optimizer services perform any processing necessary to populate value-added columns that have been added to tables in the optimizer database. For example, the StatusData Optimizer can be configured to populate the Latitude, Longitude, Speed, Bearing and Direction columns that have been added to the StatusDataT table.
The processor and optimizer services are highly-configurable and can even be run on separate machines in order to improve performance of individual services and operate within hardware limits. More details can be found in the Processor and Optimizer Services section of this guide.
Database
This section provides supplemental database-related information specific to the Data Optimizer. For information related to the adapter database, refer to the Database section in the main guide.
✱ NOTE: At this time, SQL Server is the only supported database type for the optimizer database. While multiple database types are supported for the adapter database, if all tables are to be included in a single physical database, it will need to be SQL Server. It is, however, possible to use different types of databases for the adapter and optimizer. For example, the adapter database could be PostgreSQL while the optimizer database is SQL Server. At some point in the future, support may be added for additional database types.
List of Tables
The following table lists all of the tables contained in the optimizer database along with descriptions that include the associated MyGeotab API objects, where applicable. Further detail relating to the structure and fields of individual tables can be found in the Data Dictionary section.
✱ NOTE: Each table is assigned to one of the following categories:
- Feed data: Records in feed data tables generally consist of data points collected using data feeds. Aside from value-added columns that are updated by optimizer services, unless specified otherwise, these tables are not modified once written to the database. These tables can accumulate vast quantities of records within short periods of time. It is highly recommended to have a data management strategy - especially for tables in this category.
- Reference data: These tables generally contain user-added data. Values are referenced by GeotabId in the feed data tables. Records in reference data tables can change over time and only the latest version of each record is maintained. Record counts in reference data tables tend to be small and relatively stable over time.
- System info: These tables are used by the adapter and do not offer any other specific benefit.
✱ NOTE: At this time, the Data Optimizer is limited in scope and the optimizer database contains a limited number of tables. Additional capabilities and tables will be added incrementally over time until the optimizer database eventually includes tables to warehouse all data from the adapter database. The intention of this approach is to make capabilities available as soon as possible rather than forcing everyone to wait for an extended period for a “complete” solution to be ready.
WARNING! It is possible for the database to grow very large very quickly, resulting in potential disk space and performance issues. It is important to ensure that the database is monitored and properly managed.
Table Name | Category | Description |
Feed data | Contains data corresponding to MyGeotab BinaryData objects. | |
Reference data | Contains data corresponding to MyGeotab BinaryDataType objects. | |
Reference data | Contains data corresponding to MyGeotab Controller objects. | |
Reference data | Contains data corresponding to MyGeotab Device objects. | |
Reference data | Contains data corresponding to MyGeotab Diagnostic objects. | |
Reference data | Contains data corresponding to MyGeotab Diagnostic objects. | |
Feed data | Contains data corresponding to MyGeotab DriverChange objects. | |
Feed data | Contains data corresponding to MyGeotab DriverChangeType objects. | |
Feed data | Contains data corresponding to MyGeotab FaultData objects. | |
Feed data | Contains data corresponding to MyGeotab LogRecord objects. | |
System Info | Used by the Data Optimizer for tracking and management of its various services. Data in this table should not be modified other than by the Data Optimizer itself. | |
Feed data | Contains data corresponding to MyGeotab StatusData objects. | |
Reference Data | Contains data corresponding to MyGeotab User objects. |
Data Dictionary
At this time, SQL Server is the only supported database type for the optimizer database. As such, any database-specific references such as data types related to SQL Server. The tables and views included in the optimizer database schema are detailed in the following subsections.
BinaryDataT
The BinaryDataT table contains data corresponding to MyGeotab BinaryData objects. Return to List of Tables.
Field Name | Data Type | Nullable | Description |
id | bigint | No | The unique identifier for the record in the optimizer database table. Entirely unrelated to the Geotab system. |
GeotabId | nvarchar(50) | No | The unique identifier for the specific Entity object in the Geotab system. |
BinaryTypeId | bigint | No | The Id of the BinaryDataType (in the BinaryTypesT table) associated with the subject BinaryDataT. |
ControllerId | bigint | No | The Id of the Controller (in the ControllersT table) associated with the subject BinaryDataT. |
Data | nvarchar(1024) | No | The binary data for the subject BinaryDataT. |
DateTime | datetime2(7) | Yes | The date and time of the logging of the data. |
DeviceId | bigint | No | The Id of the Device (in the DevicesT table) associated with the subject BinaryDataT. |
Version | nvarchar(50) | Yes | The version of the entity. |
RecordLastChangedUtc | datetime2(7) | No | A timestamp, in Coordinated Universal Time (UTC), indicating the last time that the subject record was modified in the optimizer database. |
BinaryTypesT
The BinaryTypesT table contains data corresponding to MyGeotab BinaryDataType objects. New records are added to this table when BinaryData objects are being processed and values for the BinaryType property that do not exist in this table are encountered. The GeotabId column represents the value of the BinaryDataType object. The id column in this table is a surrogate id that provides for efficient referencing by other tables, views and constraints. Return to List of Tables.
Field Name | Data Type | Nullable | Description |
id | bigint | No | The unique identifier for the record in the optimizer database table. Entirely unrelated to the Geotab system. |
GeotabId | nvarchar(50) | No | The value of the BinaryDataType object in the Geotab system. |
RecordLastChangedUtc | datetime2(7) | No | A timestamp, in Coordinated Universal Time (UTC), indicating the last time that the subject record was modified in the optimizer database. |
ControllersT
The ControllersT table contains data corresponding to MyGeotab Controller objects. New records are added to this table when BinaryData objects are being processed and values for the Controller property that do not exist in this table are encountered. The GeotabId column represents the Id property of the Controller object. The id column in this table is a surrogate id that provides for efficient referencing by other tables, views and constraints. Return to List of Tables.
Field Name | Data Type | Nullable | Description |
id | bigint | No | The unique identifier for the record in the optimizer database table. Entirely unrelated to the Geotab system. |
GeotabId | nvarchar(50) | No | The Id property of the Controller object in the Geotab system. |
RecordLastChangedUtc | datetime2(7) | No | A timestamp, in Coordinated Universal Time (UTC), indicating the last time that the subject record was modified in the optimizer database. |
DevicesT
The DevicesT table contains data corresponding to MyGeotab Device objects. Return to List of Tables.
Field Name | Data Type | Nullable | Description |
id | bigint | No | The unique identifier for the record in the optimizer database table. Entirely unrelated to the Geotab system. |
GeotabId | nvarchar(50) | No | The unique identifier for the specific Entity object in the Geotab system. |
ActiveFrom | datetime2(7) | Yes | The date the device is active from. |
ActiveTo | datetime2(7) | Yes | The date the device is active to. |
Comment | character varying(1024) | Yes | Free text field where any user information can be stored and referenced for this entity. |
DeviceType | nvarchar(50) | No | Specifies the GO or Custom DeviceType. |
LicensePlate | nvarchar(50) | Yes | The vehicle license plate details of the vehicle associated with the device. |
LicenseState | nvarchar(50) | Yes | The state or province of the vehicle associated with the device. |
Name | nvarchar(100) | No | The display name assigned to the device. |
ProductId | int | Yes | The product Id. Each device is assigned a unique hardware product Id. |
SerialNumber | nvarchar(12) | No | The serial number of the device. |
VIN | nvarchar(50) | Yes | The Vehicle Identification Number (VIN) of the vehicle associated with the device. |
EntityStatus | int | No | Indicates whether the subject corresponding object is active or deleted in the MyGeotab database. 1 = Active. 0 = Deleted. |
RecordLastChangedUtc | datetime2(7) | No | A timestamp, in Coordinated Universal Time (UTC), indicating the last time that the subject record was modified in the optimizer database. |
DiagnosticIdsT
The DiagnosticIdsT table contains data corresponding to MyGeotab Diagnostic objects. Return to List of Tables.
Field Name | Data Type | Nullable | Description |
id | bigint | No | The unique identifier for the record in the optimizer database table. Entirely unrelated to the Geotab system. |
GeotabGUID | nvarchar(100) | No | The underlying Globally Unique Identifier (GUID) of the Diagnostic. In the event that the GeotabId changes as a result of the assignment of a KnownId, this GeotabGUID will remain unchanged and can be used for reconciliation of Diagnostic Ids in any downstream integrations. |
GeotabId | nvarchar(100) | No | The unique identifier for the specific Entity object in the Geotab system. |
HasShimId | boolean | No | Indicates whether the Diagnostic is one that has a KnownId on the MyGeotab server side, but is unknown in the MyGeotab .NET API client (Geotab.Checkmate.ObjectModel NuGet package) used at the time of download. |
FormerShimGeotabGUID | nvarchar(100) | Yes | If there is an earlier version of the Diagnostic where HasShimId is true, this value lists the GeotabGUID of that earlier Diagnostic so that the two, along with any associated data, can be logically related. |
RecordLastChangedUtc | datetime2(7) | No | A timestamp, in Coordinated Universal Time (UTC), indicating the last time that the subject record was modified in the optimizer database. |
DiagnosticsT
The DiagnosticsT table contains data corresponding to MyGeotab Diagnostic objects. Return to List of Tables.
Field Name | Data Type | Nullable | Description |
id | bigint | No | The unique identifier for the record in the optimizer database table. Entirely unrelated to the Geotab system. |
GeotabGUID | nvarchar(100) | No | The underlying Globally Unique Identifier (GUID) of the Diagnostic. In the event that the GeotabId changes as a result of the assignment of a KnownId, this GeotabGUID will remain unchanged and can be used for reconciliation of Diagnostic Ids in any downstream integrations. |
HasShimId | boolean | No | Indicates whether the Diagnostic is one that has a KnownId on the MyGeotab server side, but is unknown in the MyGeotab .NET API client (Geotab.Checkmate.ObjectModel NuGet package) used at the time of download. |
FormerShimGeotabGUID | nvarchar(100) | Yes | If there is an earlier version of the Diagnostic where HasShimId is true, this value lists the GeotabGUID of that earlier Diagnostic so that the two, along with any associated data, can be logically related. |
ControllerId | nvarchar(100) | Yes | The applicable Controller for the diagnostic. |
DiagnosticCode | int | Yes | The diagnostic parameter code number. |
DiagnosticName | nvarchar(255) | No | The name of this entity that uniquely identifies it and is used when displaying this entity. |
DiagnosticSourceId | nvarchar(50) | No | The Id of the Source of the Diagnostic. |
DiagnosticSourceName | nvarchar(255) | No | The Name of the Source of the Diagnostic. |
DiagnosticUnitOfMeasureId | nvarchar(50) | No | The Id of the UnitOfMeasure used by the Diagnostic. |
DiagnosticUnitOfMeasureName | nvarchar(255) | No | The Name of the UnitOfMeasure used by the Diagnostic. |
OBD2DTC | nvarchar(50) | Yes | The OBD-II Diagnostic Trouble Code (DTC), if the Diagnostic is from an OBD Source. |
EntityStatus | int | No | Indicates whether the subject corresponding object is active or deleted in the MyGeotab database. 1 = Active. 0 = Deleted. |
RecordLastChangedUtc | datetime2(7) | No | A timestamp, in Coordinated Universal Time (UTC), indicating the last time that the subject record was modified in the optimizer database. |
DriverChangesT
The DriverChangesT table contains data corresponding to MyGeotab DriverChange objects. Return to List of Tables.
Field Name | Data Type | Nullable | Description |
id | bigint | No | The unique identifier for the record in the optimizer database table. Entirely unrelated to the Geotab system. |
GeotabId | nvarchar(50) | No | The unique identifier for the specific Entity object in the Geotab system. |
DateTime | datetime2(7) | Yes | The date and time of the driver change. |
DeviceId | bigint | No | The Id of the Device (in the DevicesT table) associated with the subject DriverChangeT. |
DriverId | bigint | No | The Id of the Driver (corresponding to the Id in the UsersT table) associated with the subject DriverChangeT. |
DriverChangeTypeId | bigint | No | The Id of the DriverChangeType (in the DriverChangeTypesT table) associated with the subject DriverChangeT. |
Version | bigint | No | The version of the entity. |
RecordLastChangedUtc | datetime2(7) | No | A timestamp, in Coordinated Universal Time (UTC), indicating the last time that the subject record was modified in the optimizer database. |
DriverChangeTypesT
The DriverChangeTypesT table contains data corresponding to MyGeotab DriverChangeType objects. New records are added to this table when DriverChange objects are being processed and values for the Type property that do not exist in this table are encountered. The GeotabId column represents the Type property of the DriverChange object. The id column in this table is a surrogate id that provides for efficient referencing by other tables, views and constraints. Return to List of Tables.
Field Name | Data Type | Nullable | Description |
id | bigint | No | The unique identifier for the record in the optimizer database table. Entirely unrelated to the Geotab system. |
GeotabId | nvarchar(100) | No | The Type property of the DriverChange object in the Geotab system. |
RecordLastChangedUtc | datetime2(7) | No | A timestamp, in Coordinated Universal Time (UTC), indicating the last time that the subject record was modified in the optimizer database. |
FaultDataT
The FaultDataT table contains data corresponding to MyGeotab FaultData objects. Return to List of Tables.
✱ NOTE: Fields where the Description is prefixed with a * are optionally populated by the FaultDataOptimizer service.
Field Name | Data Type | Nullable | Description |
id | bigint | No | The unique identifier for the record in the optimizer database table. Entirely unrelated to the Geotab system. |
GeotabId | nvarchar(50) | No | The unique identifier for the specific Entity object in the Geotab system. |
AmberWarningLamp | bit | Yes | Indicates whether the amber warning lamp is on. |
ClassCode | nvarchar(50) | Yes | The DtcClass code of the fault. |
ControllerId | nvarchar(100) | No | The Id of the Controller related to the fault code; if applicable. |
ControllerName | nvarchar(255) | Yes | The Name of the Controller related to the fault code; if applicable. |
Count | int | No | The number of times the fault occurred. |
DateTime | datetime2(7) | Yes | The date and time at which the event occurred. |
DeviceId | bigint | No | The Id of the Device (in the DevicesT table) associated with the subject FaultDataT. |
DiagnosticId | bigint | No | The Id of the Diagnostic (in the DiagnosticsT table) associated with the subject FaultDataT. |
DismissDateTime | datetime2(7) | Yes | The date and time that the fault was dismissed. |
DismissUserId | bigint | Yes | The Id of the User (in the UsersT table) associated with the subject FaultDataT entity. |
FailureModeCode | int | Yes | The Failure Mode Identifier (FMI) associated with the FailureMode. |
FailureModeId | nvarchar(50) | No | The Id of the FailureMode associated with the subject FaultData entity. |
FailureModeName | nvarchar(255) | Yes | The Name of the FailureMode associated with the subject FaultData entity. |
FaultLampState | nvarchar(50) | Yes | The FaultLampState of a J1939 vehicle. |
FaultState | nvarchar(50) | Yes | The FaultState code from the engine system of the specific device. |
MalfunctionLamp | bit | Yes | Indicates whether the malfunction lamp is on. |
ProtectWarningLamp | bit | Yes | Indicates whether the protect warning lamp is on. |
RedStopLamp | bit | Yes | Indicates whether the red stop lamp is on. |
Severity | nvarchar(50) | Yes | The DtcSeverity of the fault. |
SourceAddress | int | Yes | The source address for enhanced faults. |
DriverId | bigint | Yes | * The Id of the Driver (corresponding to the Id in the UsersT table) associated with the subject FaultDataT. |
Latitude | float | Yes | * The latitude of the FaultDataT record. |
Longitude | float | Yes | * The longitude of the FaultDataT record. |
Speed | real | Yes | * The speed (in km/h) of the FaultDataT record. |
Bearing | real | Yes | * The bearing (heading) in degrees of the FaultDataT record. |
Direction | nvarchar(3) | Yes | * The compass direction (e.g. “N”, “SE”, “WSW”, etc.) of the FaultDataT record. |
LongLatProcessed | bit | No | * Indicates whether the Longitude and Latitude (and by extension, Speed, Bearing and Direction) columns have been processed. |
LongLatReason | tinyint | Yes | * If not null and LongLatProcessed = true, indicates the reason why it was not possible to determine Longitude and Latitude values for the subject record. |
DriverIdProcessed | bit | No | * Indicates whether the DriverId column has been processed. |
DriverIdReason | tinyint | Yes | * If not null and DriverIdProcessed = true, indicates the reason why it was not possible to determine the DriverId value for the subject record. |
RecordLastChangedUtc | datetime2(7) | No | A timestamp, in Coordinated Universal Time (UTC), indicating the last time that the subject record was modified in the optimizer database. |
LogRecordsT
The LogRecordsT table contains data corresponding to MyGeotab LogRecord objects. Return to List of Tables.
Field Name | Data Type | Nullable | Description |
id | bigint | No | The unique identifier for the record in the optimizer database table. Entirely unrelated to the Geotab system. |
GeotabId | nvarchar(50) | No | The unique identifier for the specific Entity object in the Geotab system. |
DateTime | datetime2(7) | No | The date and time the log was recorded. |
DeviceId | bigint | No | The Id of the Device (in the DevicesT table) associated with the subject LogRecordsT. |
Latitude | float | No | The latitude of the log record. |
Longitude | float | No | The longitude of the log record. |
Speed | real | No | The logged speed or an invalid speed (in km/h). |
RecordLastChangedUtc | datetime2(7) | No | A timestamp, in Coordinated Universal Time (UTC), indicating the last time that the subject record was modified in the optimizer database. |
OProcessorTracking
The OProcessorTracking table is used by the Data Optimizer for tracking and management of its various services. Data in this table should not be modified other than by the Data Optimizer itself. Return to List of Tables.
Field Name | Data Type | Nullable | Description |
id | bigint | No | The unique identifier for the record in the optimizer database table. Entirely unrelated to the Geotab system. |
ProcessorId | nvarchar(50) | No | The unique identifier for the processor/optimizer service. |
OptimizerVersion | nvarchar(50) | Yes | The version of the Data Optimizer application that the subject processor is part of. |
OptimizerMachineName | nvarchar(100) | Yes | The name of the machine running the Data Optimizer application that the subject processor is part of. |
EntitiesLastProcessedUtc | datetime2(7) | Yes | A timestamp, in Coordinated Universal Time (UTC), indicating the last time that the subject processor completed the processing of entities. |
AdapterDbLastId | bigint | Yes | The unique identifier for the last record processed by the subject processor in the associated adapter database table. Entirely unrelated to the Geotab system. |
AdapterDbLastGeotabId | nvarchar(50) | Yes | The unique identifier for the specific Entity object in the Geotab system associated with the last record processed by the subject processor in the associated adapter database table. |
AdapterDbLastRecordCreationTimeUtcTicks | bigint | Yes | A timestamp, in Coordinated Universal Time (UTC), indicating when the last record processed by the subject processor was added to the associated table in the adapter database. Measured in ticks. A tick is equal to 100 nanoseconds or one ten-millionth of a second. There are 10,000 ticks in a millisecond and 10 million ticks in a second. |
RecordLastChangedUtc | datetime2(7) | No | A timestamp, in Coordinated Universal Time (UTC), indicating the last time that the subject record was modified in the optimizer database. |
StatusDataT
The StatusData table contains data corresponding to MyGeotab StatusData objects. Return to List of Tables.
✱ NOTE: Fields where the Description is prefixed with a * are optionally populated by the StatusDataOptimizer service.
Field Name | Data Type | Nullable | Description |
id | bigint | No | The unique identifier for the record in the optimizer database table. Entirely unrelated to the Geotab system. |
GeotabId | nvarchar(50) | No | The unique identifier for the specific Entity object in the Geotab system. |
Data | double precision | Yes | The recorded value of the diagnostic parameter. |
DateTime | datetime2(7) | Yes | The date and time of the logged event. |
DeviceId | bigint | No | The Id of the Device (in the DevicesT table) associated with the subject StatusData. |
DiagnosticId | bigint | No | The Id of the Diagnostic (in the DiagnosticsT table) associated with the subject StatusData. |
DriverId | bigint | Yes | * The Id of the Driver (corresponding to the Id in the UsersT table) associated with the subject StatusDataT. |
Latitude | float | Yes | * The latitude of the StatusDataT record. |
Longitude | float | Yes | * The longitude of the StatusDataT record. |
Speed | real | Yes | * The speed (in km/h) of the StatusDataT record. |
Bearing | real | Yes | * The bearing (heading) in degrees of the StatusDataT record. |
Direction | nvarchar(3) | Yes | * The compass direction (e.g. “N”, “SE”, “WSW”, etc.) of the StatusDataT record. |
LongLatProcessed | bit | No | * Indicates whether the Longitude and Latitude (and by extension, Speed, Bearing and Direction) columns have been processed. |
LongLatReason | tinyint | Yes | * If not null and LongLatProcessed = true, indicates the reason why it was not possible to determine Longitude and Latitude values for the subject record. |
DriverIdProcessed | bit | No | * Indicates whether the DriverId column has been processed. |
DriverIdReason | tinyint | Yes | * If not null and DriverIdProcessed = true, indicates the reason why it was not possible to determine the DriverId value for the subject record. |
RecordLastChangedUtc | datetime2(7) | No | A timestamp, in Coordinated Universal Time (UTC), indicating the last time that the subject record was modified in the optimizer database. |
UsersT
The Users table contains data corresponding to MyGeotab User objects. Return to List of Tables.
Field Name | Data Type | Nullable | Description |
id | bigint | No | The unique identifier for the record in the optimizer database table. Entirely unrelated to the Geotab system. |
GeotabId | nvarchar(50) | No | The unique identifier for the specific Entity object in the Geotab system. |
ActiveFrom | datetime2(7) | No | The date the user is active from. |
ActiveTo | datetime2(7) | No | The date the user is active to. |
EmployeeNo | nvarchar(50) | Yes | The employee number or external identifier. |
FirstName | nvarchar(255) | No | The first name of the user. |
HosRuleSet | nvarchar(255) | Yes | The HosRuleSet the user follows. Default: None. |
IsDriver | bit | No | Indicates whether the user is classified as a driver. |
LastAccessDate | datetime2(7) | Yes | A timestamp, in Coordinated Universal Time (UTC), indicating the last time that the subject user accessed the MyGeotab system. |
LastName | nvarchar(255) | No | The last name of the user. |
Name | nvarchar(255) | No | The user's email address / login name. |
RecordLastChangedUtc | datetime2(7) | No | A timestamp, in Coordinated Universal Time (UTC), indicating the last time that the subject record was modified in the optimizer database. |
Configuration Files
Two files are used to configure the Data Optimizer - appsettings.json and nlog.config. For information related to configuration of the MyGeotab API Adapter, refer to the Configuration Files section of the main guide.
appsettings.json
Aside from log-related items, all configuration settings governing operation of the Data Optimizer are found in the appsettings.json file, which is located in the same directory as the executable (i.e. MyGeotabAPIAdapter.DataOptimizer.exe). Individual settings are organized into sections for readability. The following tables provide information about the settings contained within each of these sections.
OverrideSettings
The OverrideSettings section contains settings used to override certain aspects of application logic.
Setting | Description |
DisableMachineNameValidation | Indicates whether machine name validation should be disabled. In most cases, the value should be false. It can be set to true only in cases where the application is deployed to a hosted environment in which machine names are not guaranteed to be static. WARNING! Extreme caution must be used when setting this value to true! Improper deployment could lead to application instability and data integrity issues! |
DatabaseSettings
The DatabaseSettings section contains settings used to connect to the adapter database and the optimizer database. The adapter tables and optimizer tables can reside in a single database or two separate databases. For this reason, there is a database settings section for the adapter database and a database settings section for the optimizer database. If both sets of tables are to reside in the same database, simply provide the same setting values for both sections.
✱ NOTE: At this time, SQL Server is the only supported database type for the optimizer database. While multiple database types are supported for the adapter database, if all tables are to be included in a single physical database, it will need to be SQL Server. It is, however, possible to use different types of databases for the adapter and optimizer. For example, the adapter database could be PostgreSQL while the optimizer database is SQL Server. At some point in the future, support may be added for additional database types.
DatabaseSettings - AdapterDatabase
The AdapterDatabase section under DatabaseSettings contains settings used to connect to the adapter database.
Setting | Description |
AdapterDatabaseProviderType | The database provider of the adapter database. Must be one of SQLServer, PostgreSQL or Oracle. |
AdapterDatabaseConnectionString | The adapter database connection string (e.g. |
DatabaseSettings - OptimizerDatabase
The OptimizerDatabase section under DatabaseSettings contains settings used to connect to the optimizer database.
Setting | Description |
OptimizerDatabaseProviderType | The database provider of the optimizer database. ✱ NOTE: At this time, SQL Server is the only supported database type for the optimizer database. Therefore, the value of this setting must be SQLServer. |
OptimizerDatabaseConnectionString | The adapter database connection string (e.g. |
AppSettings - GeneralSettings
The GeneralSettings section under AppSettings includes settings that do not fall into any of the other categories.
Setting | Description |
TimeoutSecondsForDatabaseTasks | The maximum number of seconds allowed for an individual adapter or optimizer database operation (select, insert, update, delete) to complete. If a database operation does not complete within this amount of time, it will be assumed that there is a loss of connectivity, the existing operation will be rolled-back and the Data Optimizer will resume normal operation after establishing that there is connectivity to the subject database (e.g. 30). Minimum: 10. Maximum: 3600. |
AppSettings - Processors
The Processors section under AppSettings includes sections that govern the operation of individual services that iteratively move batches of data from tables in the adapter database to their counterpart tables in the optimizer database.
AppSettings - Processors - BinaryData
The BinaryData section under AppSettings > Processors includes settings that govern operation of the service that is responsible for moving data from the BinaryData table in the adapter database to the BinaryDataT, BinaryTypesT and ControllersT tables in the optimizer database.
✱ NOTE: This service depends on one or more other services. See the BinaryDataProcessor section for details.
Setting | Description |
EnableBinaryDataProcessor | Indicates whether the BinaryDataProcessor service should be enabled. Must be set to either true or false. |
BinaryDataProcessorOperationMode | If set to Continuous, the BinaryDataProcessor service will keep running indefinitely. If set to Scheduled, the BinaryDataProcessor service will run indefinitely, but pause operation outside of a daily time window defined by the BinaryDataProcessorDailyStartTimeUTC and BinaryDataProcessorDailyRunTimeSeconds settings. Must be set to either Continuous or Scheduled. |
BinaryDataProcessorDailyStartTimeUTC | Only used if BinaryDataProcessorOperationMode is set to Scheduled. An ISO 8601 date and time string used to specify a time of day to serve as the start time for the daily operation window of the BinaryDataProcessor service. Only the time portion of the string is used; the date entered is irrelevant. To avoid time-zone related issues, Coordinated Universal Time (UTC) should be used (e.g. 2020-06-23T06:00:00Z). |
BinaryDataProcessorDailyRunTimeSeconds | Only used if BinaryDataProcessorOperationMode is set to Scheduled and BinaryDataProcessorDailyStartTimeUTC is set to an appropriate value. The duration, in seconds, that the BinaryDataProcessor service will run for each day, starting from the time defined in the BinaryDataProcessorDailyStartTimeUTC setting (e.g. 21600 for 6 hours). Minimum: 300 (5 minutes). Maximum: 82800 (23 hours). |
BinaryDataProcessorBatchSize | The number of records that the BinaryDataProcessor service should process during each batch/iteration. Minimum: 100. Maximum: 100000. |
BinaryDataProcessorExecutionIntervalSeconds | While the BinaryDataProcessor service is running, either continuously or within a daily operation window, if less than 1000 records are returned in a given batch/iteration, the service will pause for this duration (in seconds) before proceeding with the next batch/iteration (e.g. 60). Minimum: 10. Maximum: 86400 (1 day). This throttling mechanism is designed to prevent excessive CPU usage and database I/O when little or no data is returned as the service would otherwise needlessly iterate multiple times per second. |
AppSettings - Processors - Device
The Device section under AppSettings > Processors includes settings that govern operation of the service that is responsible for moving data from the Devices table in the adapter database to the DevicesT table in the optimizer database.
Setting | Description |
EnableDeviceProcessor | Indicates whether the DeviceProcessor service should be enabled. Must be set to either true or false. |
DeviceProcessorOperationMode | If set to Continuous, the DeviceProcessor service will keep running indefinitely. If set to Scheduled, the DeviceProcessor service will run indefinitely, but pause operation outside of a daily time window defined by the DeviceProcessorDailyStartTimeUTC and DeviceProcessorDailyRunTimeSeconds settings. Must be set to either Continuous or Scheduled. |
DeviceProcessorDailyStartTimeUTC | Only used if DeviceProcessorOperationMode is set to Scheduled. An ISO 8601 date and time string used to specify a time of day to serve as the start time for the daily operation window of the DeviceProcessor service. Only the time portion of the string is used; the date entered is irrelevant. To avoid time-zone related issues, Coordinated Universal Time (UTC) should be used (e.g. 2020-06-23T06:00:00Z). |
DeviceProcessorDailyRunTimeSeconds | Only used if DeviceProcessorOperationMode is set to Scheduled and DeviceProcessorDailyStartTimeUTC is set to an appropriate value. The duration, in seconds, that the DeviceProcessor service will run for each day, starting from the time defined in the DeviceProcessorDailyStartTimeUTC setting (e.g. 21600 for 6 hours). Minimum: 300 (5 minutes). Maximum: 82800 (23 hours). |
DeviceProcessorExecutionIntervalSeconds | While the DeviceProcessor service is running, either continuously or within a daily operation window, if no records are returned in a given batch/iteration, the service will pause for this duration (in seconds) before proceeding with the next batch/iteration (e.g. 60). Minimum: 10. Maximum: 86400 (1 day). This throttling mechanism is designed to prevent excessive CPU usage and database I/O when little or no data is returned as the service would otherwise needlessly iterate multiple times per second. |
AppSettings - Processors - Diagnostic
The Diagnostic section under AppSettings > Processors includes settings that govern operation of the service that is responsible for moving data from the Diagnostics table in the adapter database to the DiagnosticsT table in the optimizer database.
Setting | Description |
EnableDiagnosticProcessor | Indicates whether the DiagnosticProcessor service should be enabled. Must be set to either true or false. |
DiagnosticProcessorOperationMode | If set to Continuous, the DiagnosticProcessor service will keep running indefinitely. If set to Scheduled, the DiagnosticProcessor service will run indefinitely, but pause operation outside of a daily time window defined by the DiagnosticProcessorDailyStartTimeUTC and DiagnosticProcessorDailyRunTimeSeconds settings. Must be set to either Continuous or Scheduled. |
DiagnosticProcessorDailyStartTimeUTC | Only used if DiagnosticProcessorOperationMode is set to Scheduled. An ISO 8601 date and time string used to specify a time of day to serve as the start time for the daily operation window of the DiagnosticProcessor service. Only the time portion of the string is used; the date entered is irrelevant. To avoid time-zone related issues, Coordinated Universal Time (UTC) should be used (e.g. 2020-06-23T06:00:00Z). |
DiagnosticProcessorDailyRunTimeSeconds | Only used if DiagnosticProcessorOperationMode is set to Scheduled and DiagnosticProcessorDailyStartTimeUTC is set to an appropriate value. The duration, in seconds, that the DiagnosticProcessor service will run for each day, starting from the time defined in the DiagnosticProcessorDailyStartTimeUTC setting (e.g. 21600 for 6 hours). Minimum: 300 (5 minutes). Maximum: 82800 (23 hours). |
DiagnosticProcessorExecutionIntervalSeconds | While the DiagnosticProcessor service is running, either continuously or within a daily operation window, if no records are returned in a given batch/iteration, the service will pause for this duration (in seconds) before proceeding with the next batch/iteration (e.g. 60). Minimum: 10. Maximum: 86400 (1 day). This throttling mechanism is designed to prevent excessive CPU usage and database I/O when little or no data is returned as the service would otherwise needlessly iterate multiple times per second. |
AppSettings - Processors - DriverChange
The DriverChange section under AppSettings > Processors includes settings that govern operation of the service that is responsible for moving data from the DriverChanges table in the adapter database to the DriverChangesT and DriverChangeTypesT tables in the optimizer database.
✱ NOTE: This service depends on one or more other services. See the DriverChangeProcessor section for details.
Setting | Description |
EnableDriverChangeProcessor | Indicates whether the DriverChangeProcessor service should be enabled. Must be set to either true or false. |
DriverChangeProcessorOperationMode | If set to Continuous, the DriverChangeProcessor service will keep running indefinitely. If set to Scheduled, the DriverChangeProcessor service will run indefinitely, but pause operation outside of a daily time window defined by the DriverChangeProcessorDailyStartTimeUTC and DriverChangeProcessorDailyRunTimeSeconds settings. Must be set to either Continuous or Scheduled. |
DriverChangeProcessorDailyStartTimeUTC | Only used if DriverChangeProcessorOperationMode is set to Scheduled. An ISO 8601 date and time string used to specify a time of day to serve as the start time for the daily operation window of the DriverChangeProcessor service. Only the time portion of the string is used; the date entered is irrelevant. To avoid time-zone related issues, Coordinated Universal Time (UTC) should be used (e.g. 2020-06-23T06:00:00Z). |
DriverChangeProcessorDailyRunTimeSeconds | Only used if DriverChangeProcessorOperationMode is set to Scheduled and DriverChangeProcessorDailyStartTimeUTC is set to an appropriate value. The duration, in seconds, that the DriverChangeProcessor service will run for each day, starting from the time defined in the DriverChangeProcessorDailyStartTimeUTC setting (e.g. 21600 for 6 hours). Minimum: 300 (5 minutes). Maximum: 82800 (23 hours). |
DriverChangeProcessorBatchSize | The number of records that the DriverChangeProcessor service should process during each batch/iteration. Minimum: 100. Maximum: 100000. |
DriverChangeProcessorExecutionIntervalSeconds | While the DriverChangeProcessor service is running, either continuously or within a daily operation window, if less than 1000 records are returned in a given batch/iteration, the service will pause for this duration (in seconds) before proceeding with the next batch/iteration (e.g. 60). Minimum: 10. Maximum: 86400 (1 day). This throttling mechanism is designed to prevent excessive CPU usage and database I/O when little or no data is returned as the service would otherwise needlessly iterate multiple times per second. |
AppSettings - Processors - FaultData
The FaultData section under AppSettings > Processors includes settings that govern operation of the service that is responsible for moving data from the FaultData table in the adapter database to the FaultDataT table in the optimizer database.
✱ NOTE: This service depends on one or more other services. See the FaultDataProcessor section for details.
Setting | Description |
EnableFaultDataProcessor | Indicates whether the FaultDataProcessor service should be enabled. Must be set to either true or false. |
FaultDataProcessorOperationMode | If set to Continuous, the FaultDataProcessor service will keep running indefinitely. If set to Scheduled, the FaultDataProcessor service will run indefinitely, but pause operation outside of a daily time window defined by the FaultDataProcessorDailyStartTimeUTC and FaultDataProcessorDailyRunTimeSeconds settings. Must be set to either Continuous or Scheduled. |
FaultDataProcessorDailyStartTimeUTC | Only used if FaultDataProcessorOperationMode is set to Scheduled. An ISO 8601 date and time string used to specify a time of day to serve as the start time for the daily operation window of the FaultDataProcessor service. Only the time portion of the string is used; the date entered is irrelevant. To avoid time-zone related issues, Coordinated Universal Time (UTC) should be used (e.g. 2020-06-23T06:00:00Z). |
FaultDataProcessorDailyRunTimeSeconds | Only used if FaultDataProcessorOperationMode is set to Scheduled and FaultDataProcessorDailyStartTimeUTC is set to an appropriate value. The duration, in seconds, that the FaultDataProcessor service will run for each day, starting from the time defined in the FaultDataProcessorDailyStartTimeUTC setting (e.g. 21600 for 6 hours). Minimum: 300 (5 minutes). Maximum: 82800 (23 hours). |
FaultDataProcessorBatchSize | The number of records that the FaultDataProcessor service should process during each batch/iteration. Minimum: 100. Maximum: 100000. |
FaultDataProcessorExecutionIntervalSeconds | While the FaultDataProcessor service is running, either continuously or within a daily operation window, if less than 1000 records are returned in a given batch/iteration, the service will pause for this duration (in seconds) before proceeding with the next batch/iteration (e.g. 60). Minimum: 10. Maximum: 86400 (1 day). This throttling mechanism is designed to prevent excessive CPU usage and database I/O when little or no data is returned as the service would otherwise needlessly iterate multiple times per second. |
AppSettings - Processors - LogRecord
The LogRecord section under AppSettings > Processors includes settings that govern operation of the service that is responsible for moving data from the LogRecords table in the adapter database to the LogRecordsT table in the optimizer database.
✱ NOTE: This service depends on one or more other services. See the LogRecordProcessor section for details.
Setting | Description |
EnableLogRecordProcessor | Indicates whether the LogRecordProcessor service should be enabled. Must be set to either true or false. |
LogRecordProcessorOperationMode | If set to Continuous, the LogRecordProcessor service will keep running indefinitely. If set to Scheduled, the LogRecordProcessor service will run indefinitely, but pause operation outside of a daily time window defined by the LogRecordProcessorDailyStartTimeUTC and LogRecordProcessorDailyRunTimeSeconds settings. Must be set to either Continuous or Scheduled. |
LogRecordProcessorDailyStartTimeUTC | Only used if LogRecordProcessorOperationMode is set to Scheduled. An ISO 8601 date and time string used to specify a time of day to serve as the start time for the daily operation window of the LogRecordProcessor service. Only the time portion of the string is used; the date entered is irrelevant. To avoid time-zone related issues, Coordinated Universal Time (UTC) should be used (e.g. 2020-06-23T06:00:00Z). |
LogRecordProcessorDailyRunTimeSeconds | Only used if LogRecordProcessorOperationMode is set to Scheduled and LogRecordProcessorDailyStartTimeUTC is set to an appropriate value. The duration, in seconds, that the LogRecordProcessor service will run for each day, starting from the time defined in the LogRecordProcessorDailyStartTimeUTC setting (e.g. 21600 for 6 hours). Minimum: 300 (5 minutes). Maximum: 82800 (23 hours). |
LogRecordProcessorBatchSize | The number of records that the LogRecordProcessor service should process during each batch/iteration. Minimum: 100. Maximum: 100000. |
LogRecordProcessorExecutionIntervalSeconds | While the LogRecordProcessor service is running, either continuously or within a daily operation window, if less than 1000 records are returned in a given batch/iteration, the service will pause for this duration (in seconds) before proceeding with the next batch/iteration (e.g. 60). Minimum: 10. Maximum: 86400 (1 day). This throttling mechanism is designed to prevent excessive CPU usage and database I/O when little or no data is returned as the service would otherwise needlessly iterate multiple times per second. |
AppSettings - Processors - StatusData
The StatusData section under AppSettings > Processors includes settings that govern operation of the service that is responsible for moving data from the StatusData table in the adapter database to the StatusDataT table in the optimizer database.
✱ NOTE: This service depends on one or more other services. See the StatusDataProcessor section for details.
Setting | Description |
EnableStatusDataProcessor | Indicates whether the StatusDataProcessor service should be enabled. Must be set to either true or false. |
StatusDataProcessorOperationMode | If set to Continuous, the StatusDataProcessor service will keep running indefinitely. If set to Scheduled, the StatusDataProcessor service will run indefinitely, but pause operation outside of a daily time window defined by the StatusDataProcessorDailyStartTimeUTC and StatusDataProcessorDailyRunTimeSeconds settings. Must be set to either Continuous or Scheduled. |
StatusDataProcessorDailyStartTimeUTC | Only used if StatusDataProcessorOperationMode is set to Scheduled. An ISO 8601 date and time string used to specify a time of day to serve as the start time for the daily operation window of the StatusDataProcessor service. Only the time portion of the string is used; the date entered is irrelevant. To avoid time-zone related issues, Coordinated Universal Time (UTC) should be used (e.g. 2020-06-23T06:00:00Z). |
StatusDataProcessorDailyRunTimeSeconds | Only used if StatusDataProcessorOperationMode is set to Scheduled and StatusDataProcessorDailyStartTimeUTC is set to an appropriate value. The duration, in seconds, that the StatusDataProcessor service will run for each day, starting from the time defined in the StatusDataProcessorDailyStartTimeUTC setting (e.g. 21600 for 6 hours). Minimum: 300 (5 minutes). Maximum: 82800 (23 hours). |
StatusDataProcessorBatchSize | The number of records that the StatusDataProcessor service should process during each batch/iteration. Minimum: 100. Maximum: 100000. |
StatusDataProcessorExecutionIntervalSeconds | While the StatusDataProcessor service is running, either continuously or within a daily operation window, if less than 1000 records are returned in a given batch/iteration, the service will pause for this duration (in seconds) before proceeding with the next batch/iteration (e.g. 60). Minimum: 10. Maximum: 86400 (1 day). This throttling mechanism is designed to prevent excessive CPU usage and database I/O when little or no data is returned as the service would otherwise needlessly iterate multiple times per second. |
AppSettings - Processors - User
The User section under AppSettings > Processors includes settings that govern operation of the service that is responsible for moving data from the Users table in the adapter database to the UsersT table in the optimizer database.
Setting | Description |
EnableUserProcessor | Indicates whether the UserProcessor service should be enabled. Must be set to either true or false. |
UserProcessorOperationMode | If set to Continuous, the UserProcessor service will keep running indefinitely. If set to Scheduled, the UserProcessor service will run indefinitely, but pause operation outside of a daily time window defined by the UserProcessorDailyStartTimeUTC and UserProcessorDailyRunTimeSeconds settings. Must be set to either Continuous or Scheduled. |
UserProcessorDailyStartTimeUTC | Only used if UserProcessorOperationMode is set to Scheduled. An ISO 8601 date and time string used to specify a time of day to serve as the start time for the daily operation window of the UserProcessor service. Only the time portion of the string is used; the date entered is irrelevant. To avoid time-zone related issues, Coordinated Universal Time (UTC) should be used (e.g. 2020-06-23T06:00:00Z). |
UserProcessorDailyRunTimeSeconds | Only used if UserProcessorOperationMode is set to Scheduled and UserProcessorDailyStartTimeUTC is set to an appropriate value. The duration, in seconds, that the UserProcessor service will run for each day, starting from the time defined in the UserProcessorDailyStartTimeUTC setting (e.g. 21600 for 6 hours). Minimum: 300 (5 minutes). Maximum: 82800 (23 hours). |
UserProcessorExecutionIntervalSeconds | While the UserProcessor service is running, either continuously or within a daily operation window, if no records are returned in a given batch/iteration, the service will pause for this duration (in seconds) before proceeding with the next batch/iteration (e.g. 60). Minimum: 10. Maximum: 86400 (1 day). This throttling mechanism is designed to prevent excessive CPU usage and database I/O when little or no data is returned as the service would otherwise needlessly iterate multiple times per second. |
AppSettings - Optimizers
The Optimizers section under AppSettings includes sections that govern the operation of individual services that perform any processing necessary to populate value-added columns that have been added to tables in the optimizer database.
AppSettings - Optimizers - FaultData
The FaultData section under AppSettings > Optimizers includes settings that govern operation of the service that is responsible for any processing necessary to populate value-added columns that have been added to the FaultDataT table in the optimizer database.
✱ NOTE: This service depends on one or more other services. See the FaultDataOptimizer section for details.
Setting | Description |
EnableFaultDataOptimizer | Indicates whether the FaultDataOptimizer service should be enabled. Must be set to either true or false. |
FaultDataOptimizerOperationMode | If set to Continuous, the FaultDataOptimizer service will keep running indefinitely. If set to Scheduled, the FaultDataOptimizer service will run indefinitely, but pause operation outside of a daily time window defined by the FaultDataOptimizerDailyStartTimeUTC and FaultDataOptimizerDailyRunTimeSeconds settings. Must be set to either Continuous or Scheduled. |
FaultDataOptimizerDailyStartTimeUTC | Only used if FaultDataOptimizerOperationMode is set to Scheduled. An ISO 8601 date and time string used to specify a time of day to serve as the start time for the daily operation window of the FaultDataOptimizer service. Only the time portion of the string is used; the date entered is irrelevant. To avoid time-zone related issues, Coordinated Universal Time (UTC) should be used (e.g. 2020-06-23T06:00:00Z). |
FaultDataOptimizerDailyRunTimeSeconds | Only used if FaultDataOptimizerOperationMode is set to Scheduled and FaultDataOptimizerDailyStartTimeUTC is set to an appropriate value. The duration, in seconds, that the FaultDataOptimizer service will run for each day, starting from the time defined in the FaultDataOptimizerDailyStartTimeUTC setting (e.g. 21600 for 6 hours). Minimum: 300 (5 minutes). Maximum: 82800 (23 hours). |
FaultDataOptimizerExecutionIntervalSeconds | While the FaultDataOptimizer service is running, either continuously or within a daily operation window, if fewer than 100 records are processed in a given batch/iteration, the service will pause for this duration (in seconds) before proceeding with the next batch/iteration. If 100 or more records are processed in a given batch/iteration, the FaultDataOptimizer will immediately retrieve the next batch of records for processing (e.g. 60). Minimum: 10. Maximum: 86400 (1 day). This throttling mechanism is designed to maximize throughput while preventing excessive CPU usage and database I/O when little or no data is returned as the service would otherwise needlessly iterate multiple times per second. |
FaultDataOptimizerPopulateLongitudeLatitude | Indicates whether the FaultDataOptimizer service should populate the Longitude and Latitude columns in the FaultDataT table. Must be set to either true or false. |
FaultDataOptimizerPopulateSpeed | Only used if FaultDataOptimizerPopulateLongitudeLatitude is set to true. Indicates whether the FaultDataOptimizer service should populate the Speed column in the FaultDataT table. Must be set to either true or false. |
FaultDataOptimizerPopulateBearing | Only used if FaultDataOptimizerPopulateLongitudeLatitude is set to true. Indicates whether the FaultDataOptimizer service should populate the Bearing column in the FaultDataT table. Must be set to either true or false. |
FaultDataOptimizerPopulateDirection | Only used if FaultDataOptimizerPopulateLongitudeLatitude is set to true. Indicates whether the FaultDataOptimizer service should populate the Direction column in the FaultDataT table. Must be set to either true or false. |
FaultDataOptimizerNumberOfCompassDirections | Only used if FaultDataOptimizerPopulateLongitudeLatitude and FaultDataOptimizerPopulateDirection are both set to true. Indicates the number of cardinal directions (on the compass rose) to use when determining direction based on the Bearing value. Must be one of 4, 8, or 16. |
FaultDataOptimizerPopulateDriverId | Indicates whether the FaultDataOptimizer service should populate the DriverId column in the FaultDataT table. Must be set to either true or false. |
AppSettings - Optimizers - StatusData
The StatusData section under AppSettings > Optimizers includes settings that govern operation of the service that is responsible for any processing necessary to populate value-added columns that have been added to the StatusDataT table in the optimizer database.
✱ NOTE: This service depends on one or more other services. See the StatusDataOptimizer section for details.
Setting | Description |
EnableStatusDataOptimizer | Indicates whether the StatusDataOptimizer service should be enabled. Must be set to either true or false. |
StatusDataOptimizerOperationMode | If set to Continuous, the StatusDataOptimizer service will keep running indefinitely. If set to Scheduled, the StatusDataOptimizer service will run indefinitely, but pause operation outside of a daily time window defined by the StatusDataOptimizerDailyStartTimeUTC and StatusDataOptimizerDailyRunTimeSeconds settings. Must be set to either Continuous or Scheduled. |
StatusDataOptimizerDailyStartTimeUTC | Only used if StatusDataOptimizerOperationMode is set to Scheduled. An ISO 8601 date and time string used to specify a time of day to serve as the start time for the daily operation window of the StatusDataOptimizer service. Only the time portion of the string is used; the date entered is irrelevant. To avoid time-zone related issues, Coordinated Universal Time (UTC) should be used (e.g. 2020-06-23T06:00:00Z). |
StatusDataOptimizerDailyRunTimeSeconds | Only used if StatusDataOptimizerOperationMode is set to Scheduled and StatusDataOptimizerDailyStartTimeUTC is set to an appropriate value. The duration, in seconds, that the StatusDataOptimizer service will run for each day, starting from the time defined in the StatusDataOptimizerDailyStartTimeUTC setting (e.g. 21600 for 6 hours). Minimum: 300 (5 minutes). Maximum: 82800 (23 hours). |
StatusDataOptimizerExecutionIntervalSeconds | While the StatusDataOptimizer service is running, either continuously or within a daily operation window, if fewer than 500 records are processed in a given batch/iteration, the service will pause for this duration (in seconds) before proceeding with the next batch/iteration (e.g. 60). Minimum: 10. Maximum: 86400 (1 day). This throttling mechanism is designed to maximize throughput while preventing excessive CPU usage and database I/O when little or no data is returned as the service would otherwise needlessly iterate multiple times per second. |
StatusDataOptimizerPopulateLongitudeLatitude | Indicates whether the StatusDataOptimizer service should populate the Longitude and Latitude columns in the StatusDataT table. Must be set to either true or false. |
StatusDataOptimizerPopulateSpeed | Only used if StatusDataOptimizerPopulateLongitudeLatitude is set to true. Indicates whether the StatusDataOptimizer service should populate the Speed column in the StatusDataT table. Must be set to either true or false. |
StatusDataOptimizerPopulateBearing | Only used if StatusDataOptimizerPopulateLongitudeLatitude is set to true. Indicates whether the StatusDataOptimizer service should populate the Bearing column in the StatusDataT table. Must be set to either true or false. |
StatusDataOptimizerPopulateDirection | Only used if StatusDataOptimizerPopulateLongitudeLatitude is set to true. Indicates whether the StatusDataOptimizer service should populate the Direction column in the StatusDataT table. Must be set to either true or false. |
StatusDataOptimizerNumberOfCompassDirections | Only used if StatusDataOptimizerPopulateLongitudeLatitude and StatusDataOptimizerPopulateDirection are both set to true. Indicates the number of cardinal directions (on the compass rose) to use when determining direction based on the Bearing value. Must be one of 4, 8, or 16. |
StatusDataOptimizerPopulateDriverId | Indicates whether the StatusDataOptimizer service should populate the DriverId column in the StatusDataT table. Must be set to either true or false. |
nlog.config
The Data Optimizer utilizes the NLog LoggerProvider for Microsoft.Extensions.Logging to capture information and write it to log files for debugging purposes. NLog configuration settings are found in the nlog.config file, which is located in the same directory as the executable (i.e. MyGeotabAPIAdapter.DataOptimizer.exe).
Below is the content of the nlog.config file that is included with the MyGeotab API Adapter. It is followed by instructions that indicate how the highlighted settings may be adjusted.
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" autoReload="true" internalLogFile="LOG-MyGeotab_API_Adapter-internal.log" internalLogLevel="Error" >
maxArchiveFiles="100" archiveAboveSize="5120000" archiveEvery="Day">
layout="${date}|${level:uppercase=true}|${message} ${exception}|${logger}|${all-event-properties}" />
minlevel="Info" writeTo="target1,target2" />
|
WARNING! Only the settings that are highlighted in the above content should be modified as described in the following table. Changing anything else could lead to unpredictable consequences
The following table lists the NLog settings, highlighted above, that may be adjusted as required.
Setting | Description |
autoReload | Indicates whether the nlog.config file should be watched for changes and reloaded automatically when changed. Must be set to either true or false. |
maxArchiveFiles | Maximum number of archive files that should be kept. If maxArchiveFiles is less or equal to 0, old files aren't deleted. Default: 100. |
archiveAboveSize | Size in bytes above which log files will be automatically archived. Default: 5120000 (5 MB). |
archiveEvery | Indicates whether to automatically archive log files every time the specified time passes. Default: DAY. Possible values:
|
minlevel | Indicates the log level, which is the amount of detail to be written to log files. Default: Debug. Possible values:
|
Processor and Optimizer Services
The Data Optimizer includes two types of services - processors and optimizers. Processors move data from the adapter database to the optimizer database and optimizers then populate value-added columns in the optimizer database tables. Information pertaining to each of the processors and optimizers is provided in the following subsections.
Service Interdependencies and Surrogate Ids
The optimizer database takes a normalized form in which physical relationships are used to link logically-related records from multiple tables. This is done primarily to maximize performance and data integrity while reducing data redundancy. Surrogate IDs, generally of the bigint data type, are used in place of the string-based GeotabId values to identify records representing entities originating in the Geotab platform. Related tables are linked to each other using these surrogate IDs and referential constraints prevent the use of invalid IDs. Certain interdependencies are created as a result of this database structure. For example, the DeviceId column in the LogRecordsT table is related to the id column in the DevicesT table. As a result, when processing LogRecords, in order to add a record to the LogRecordsT table, it is first necessary to obtain the id of the record in the DevicesT table whose GeotabId matches the GeotabId of the LogRecord being processed. Then, the new record can be added to the LogRecordsT table supplying this id as the DeviceId.
Tabular interdependencies at the database level result in interdependencies between services at the application level. Continuing with the example from the previous paragraph, in order for the LogRecordProcessor to be able to write data to the LogRecordsT table, the DeviceProcessor must be running and must have already written data to the DevicesT table so that the id values can be obtained to use as the corresponding DeviceId values in the LogRecordsT table.
Each optimizer service includes logic that ensures any other services on which it depends (i.e. its prerequisite services) have been run at least within the last two days. In the event that a service’s prerequisite services are not running, a message will be logged indicating which prerequisite services were found not to be running and the dependent service will pause operation - checking every five minutes until the prerequisite services are found to be operating. This provides administrators the ability to start-up those other services without having to restart all services and is particularly useful in multi-server deployments where processor and optimizer services are spread across multiple machines.
Service Dependency Graph
The following table shows the interdependencies between the various processor and optimizer services. Note that all optimizer services operate on the data that resides in their respective tables, resulting in an implicit dependence on the associated processor services (i.e. if a processor service has not written any data to a table, the associated optimizer service will not have any data to work with). However, these implicit dependencies are not listed below.
Service | Prerequisite Services |
BinaryDataProcessor | DeviceProcessor |
DeviceProcessor | None |
DiagnosticProcessor | None |
DriverChangeProcessor | DeviceProcessor, UserProcessor |
FaultDataOptimizer | None |
FaultDataProcessor | DeviceProcessor, DiagnosticProcessor, UserProcessor |
LogRecordProcessor | DeviceProcessor |
StatusDataOptimizer | None |
StatusDataProcessor | DeviceProcessor, DiagnosticProcessor |
UserProcessor | None |
LongLatReason Codes
Sometimes, when processing a FaultDataT or StatusDataT record, referred to in this section as the “subject record”, it is not possible to interpolate longitude and latitude values and it is determined by the subject optimizer (e.g. FaultDataOptimizer, StatusDataOptimizer, etc.) that it will never be possible to do so. In such cases, the LongLatProcessed field will be set to 1 (i.e. “true”) to prevent the subject record from being included in future batches. Additionally, the LongLatReason will be populated with a value indicating the reason why it is not possible to interpolate these values. The following table lists the reasons:
LongLatReason Value | Description |
NULL |
|
1 | Lag and lead LogRecordT records could not be found for the DateTime of the subject record. |
2 | This is a data validation check and should not be encountered. The DateTime of the lead LogRecordT record is less than that of the lag LogRecordT record - both of which the subject record was associated with. |
3 | This is a data validation check and should not be encountered. The DateTime of the subject record is greater than that of the associated lead LogRecordT record. |
4 | This is a data validation check and should not be encountered. The DateTime of the subject record is less than that of the associated lag LogRecordT record. |
5 | The DateTime of the subject record is older than the DateTime of any LogRecordT records. It is highly unlikely that new LogRecords with older dates will come-in, since the MyGeotab API Adapter only moves forward in time once started. |
6 | The DateTime of the subject record is older than the DateTime of any LogRecordT records for the associated Device. It is highly unlikely that new LogRecords with older dates will come-in, since the MyGeotab API Adapter only moves forward in time once started. |
DriverIdReason Codes
Sometimes, when processing a FaultDataT or StatusDataT record, referred to in this section as the “subject record”, it is not possible to estimate a DriverId value and it is determined by the subject optimizer (e.g. FaultDataOptimizer, StatusDataOptimizer, etc.) that it will never be possible to do so. In such cases, the DriverIdProcessed field will be set to 1 (i.e. “true”) to prevent the subject record from being included in future batches. Additionally, the DriverIdReason will be populated with a value indicating the reason why it is not possible to determine the DriverId. The following table lists the reasons:
LongLatReason Value | Description |
NULL | |
1 | The DateTime of the subject record is older than the DateTime of any DriverChangesT records. It is highly unlikely that new DriverChangesT records with older dates will come-in, since the MyGeotab API Adapter only moves forward in time once started. |
2 | The DateTime of the subject record is older than the DateTime of any DriverChangesT records for the associated Device. It is highly unlikely that new DriverChangesT records with older dates will come-in, since the MyGeotab API Adapter only moves forward in time once started. |
3 | A lag DriverChangesT record could not be found for the DateTime of the subject record. |
BinaryDataProcessor
The BinaryDataProcessor moves data from the BinaryData table in the adapter database to the BinaryDataT table in the optimizer database. It also adds records to the BinaryTypesT and ControllersT tables when new values are found in the BinaryData.BinaryType and BinaryData.ControllerId fields, respectively.
✱ NOTE: This service depends on one or more other services. See the Service Dependency Graph for details.
DeviceProcessor
The DeviceProcessor synchronizes the DevicesT table of the optimizer database with the Devices table of the adapter database. During each iteration, a check is performed to identify any new or changed records in the Devices table. For each new record, a corresponding new record is added to the DevicesT table. For each changed record, the corresponding DevicesT record is updated accordingly.
DiagnosticProcessor
The DiagnosticProcessor synchronizes the DiagnosticsT table of the optimizer database with the Diagnostics table of the adapter database. During each iteration, a check is performed to identify any new or changed records in the Diagnostics table. For each new record, a corresponding new record is added to the DiagnosticsT table. For each changed record, the corresponding DiagnosticsT record is updated accordingly.
DriverChangeProcessor
The DriverChangeProcessor moves data from the DriverChanges table in the adapter database to the DriverChangesT table in the optimizer database and adds a record to the DriverChangeTypesT table each time a new value is found in the DriverChanges.Type field.
✱ NOTE: This service depends on one or more other services. See the Service Dependency Graph for details.
FaultDataProcessor
The FaultDataProcessor moves data from the FaultData table in the adapter database to the FaultDataT table in the optimizer database.
✱ NOTE: This service depends on one or more other services. See the Service Dependency Graph for details.
FaultDataOptimizer
The FaultDataOptimizer populates value-added columns in the FaultDataT table of the optimizer database based on the values of the settings in the AppSettings - Optimizers - FaultData section of the appsettings.json file.
Populating Columns: Latitude, Longitude, Speed, Bearing and Direction
During each iteration, a complex database query is executed to retrieve a batch of FaultDataT records with additional information from the lag and lead LogRecordsT records (i.e. for each FaultDataT record in the batch, information is included from the LogRecordsT records with the closest preceding and succeeding DateTime values as compared to the DateTime value of the subject FaultDataT record). Using this information, for each FaultDataT record:
- The longitude and latitude values are interpolated, assuming a constant speed between the lag and lead LogRecords, to derive coordinates of the device/vehicle at the time the FaultData record was captured.
- The bearing between the lag and lead LogRecords is calculated.
- The compass direction corresponding with the calculated bearing is determined.
- If configured to populate Speed, the Speed value of the lag LogRecordsT record is used.
- The Latitude, Longitude, Speed, Bearing and Direction fields of the FaultDataT record are populated with the above values based on the configured settings.
- The LongLatProcessed field will be set to 1 (i.e. “true”) to prevent the FaultDataT record from being included in future batches.
- The longitude and latitude values are interpolated, assuming a constant speed between the lag and lead LogRecords, to derive coordinates of the device/vehicle at the time the StatusData record was captured.
- The bearing between the lag and lead LogRecords is calculated.
- The compass direction corresponding with the calculated bearing is determined.
- If configured to populate Speed, the Speed value of the lag LogRecordsT record is used.
- The Latitude, Longitude, Speed, Bearing and Direction fields of the StatusDataT record are populated with the above values based on the configured settings.
- The LongLatProcessed field will be set to 1 (i.e. “true”) to prevent the StatusDataT record from being included in future batches.
Populating Columns: LongLatProcessed and LongLatReason
When a FaultDataT record is processed, the LongLatProcessed field will be set to 1 (i.e. “true”) to prevent the FaultDataT record from being included or reprocessed in future batches. If the longitude and latitude coordinates are successfully interpolated, the LongLatReason field will be null. Sometimes, it is not possible to interpolate longitude and latitude values and it is determined that it will never be possible to do so. In such cases, the LongLatReason will be populated with a value indicating the reason why it is not possible to interpolate these values. Refer to the LongLatReason Codes section for the list of possible values and their descriptions.
Populating Column: DriverId
During each iteration, a database query is executed to retrieve a batch of FaultDataT records with additional information from the lag DriverChangesT records (i.e. for each FaultDataT record in the batch, information is included from the DriverChangesT record with the closest preceding DateTime value as compared to the DateTime value of the subject FaultDataT record). The DriverId of the lag DriverChangesT record is applied to the DriverId field of the subject FaultDataT record.
Populating Columns: DriverIdProcessed and DriverIdReason
When a FaultDataT record is processed, the DriverIdProcessed field will be set to 1 (i.e. “true”) to prevent the FaultDataT record from being included or reprocessed in future batches. If the DriverId is successfully estimated, the DriverIdReason field will be null. Sometimes, it is not possible to estimate a DriverId value and it is determined that it will never be possible to do so. In such cases, the DriverIdReason will be populated with a value indicating the reason why it is not possible to estimate this value. Refer to the DriverIdReason Codes section for the list of possible values and their descriptions.
FaultDataOptimizer Throttling
While the FaultDataOptimizer service is running, either continuously or within a daily operation window, if fewer than 100 records are processed in a given batch/iteration, the service will pause for the duration specified by the value of the FaultDataOptimizerExecutionIntervalSeconds setting in appsettings.json before proceeding with the next batch/iteration. If 100 or more records are processed in a given batch/iteration, the FaultDataOptimizer will immediately retrieve the next batch of records for processing. This throttling mechanism is designed to maximize throughput while preventing excessive CPU usage and database I/O when little or no data is returned as the service would otherwise needlessly iterate multiple times per second.
✱ NOTE: The FaultDataOptimizer will throttle often when compared to other optimizer services such as the StatusDataOptimizer. This is to be expected due to the frequency differences between FaultData entities and other types of entities. More detail is provided below.
When compared to other optimizer services such as the StatusDataOptimizer, for example, it may be noted that the FaultDataOptimizer spends a disproportionate amount of time being throttled. This is due to the fact that FaultData is generally much less frequent than other types of data. For instance a single batch of 50,000 FaultData records may represent many months worth of FaultData. However, the same number of LogRecords might be collected within a week. As such, the LogRecordProcessor needs to execute many iterations to retrieve all the LogRecords to cover the timespan elapsed in a single batch of FaultDataRecords. The FaultDataOptimizer, in turn, must wait until all of the LogRecords have been obtained before it is possible to use them for interpolating location information for the FaultData records.
LogRecordProcessor
The LogRecordProcessor moves data from the LogRecords table in the adapter database to the LogRecordsT table in the optimizer database.
✱ NOTE: This service depends on one or more other services. See the Service Dependency Graph for details.
StatusDataProcessor
The StatusDataProcessor moves data from the StatusData table in the adapter database to the StatusDataT table in the optimizer database.
✱ NOTE: This service depends on one or more other services. See the Service Dependency Graph for details.
StatusDataOptimizer
The StatusDataOptimizer populates value-added columns in the StatusDataT table of the optimizer database based on the values of the settings in the AppSettings - Optimizers - StatusData section of the appsettings.json file.
Populating Columns: Latitude, Longitude, Speed, Bearing and Direction
During each iteration, a complex database query is executed to retrieve a batch of StatusDataT records with additional information from the lag and lead LogRecordsT records (i.e. for each StatusDataT record in the batch, information is included from the LogRecordsT records with the closest preceding and succeeding DateTime values as compared to the DateTime value of the subject StatusDataT record). Using this information, for each StatusDataT record:
Populating Columns: LongLatProcessed and LongLatReason
When a StatusDataT record is processed, the LongLatProcessed field will be set to 1 (i.e. “true”) to prevent the StatusDataT record from being included or reprocessed in future batches. If the longitude and latitude coordinates are successfully interpolated, the LongLatReason field will be null. Sometimes, it is not possible to interpolate longitude and latitude values and it is determined that it will never be possible to do so. In such cases, the LongLatReason will be populated with a value indicating the reason why it is not possible to interpolate these values. Refer to the LongLatReason Codes section for the list of possible values and their descriptions.
Populating Column: DriverId
During each iteration, a database query is executed to retrieve a batch of StatusDataT records with additional information from the lag DriverChangesT records (i.e. for each StatusDataT record in the batch, information is included from the DriverChangesT record with the closest preceding DateTime value as compared to the DateTime value of the subject StatusDataT record). The DriverId of the lag DriverChangesT record is applied to the DriverId field of the subject StatusDataT record.
Populating Columns: DriverIdProcessed and DriverIdReason
When a StatusDataT record is processed, the DriverIdProcessed field will be set to 1 (i.e. “true”) to prevent the StatusDataT record from being included or reprocessed in future batches. If the DriverId is successfully estimated, the DriverIdReason field will be null. Sometimes, it is not possible to estimate a DriverId value and it is determined that it will never be possible to do so. In such cases, the DriverIdReason will be populated with a value indicating the reason why it is not possible to estimate this value. Refer to the DriverIdReason Codes section for the list of possible values and their descriptions.
StatusDataOptimizer Throttling
While the StatusDataOptimizer service is running, either continuously or within a daily operation window, if fewer than 500 records are processed in a given batch/iteration, the service will pause for the duration specified by the value of the StatusDataOptimizerExecutionIntervalSeconds setting in appsettings.json before proceeding with the next batch/iteration. If 500 or more records are processed in a given batch/iteration, the StatusDataOptimizer will immediately retrieve the next batch of records for processing. This throttling mechanism is designed to maximize throughput while preventing excessive CPU usage and database I/O when little or no data is returned as the service would otherwise needlessly iterate multiple times per second.
UserProcessor
The UserProcessor synchronizes the UsersT table of the optimizer database with the Users table of the adapter database. During each iteration, a check is performed to identify any new or changed records in the Users table. For each new record, a corresponding new record is added to the UsersT table. For each changed record, the corresponding UsersT record is updated accordingly.
Solution Usage and Implementation
! IMPORTANT: The Data Optimizer builds on top of the foundation laid by the MyGeotab API Adapter. Before proceeding with any of the steps outlined in this section, it is necessary to follow the Solution Usage and Implementation section of the MyGeotab API Adapter - Solution and Implementation Guide.
Broad steps to implement the Data Optimizer are:
1 | Download and deploy the latest release of the MyGeotab API Adapter from GitHub. See the Solution Usage and Implementation section of the MyGeotab API Adapter - Solution and Implementation Guide for details. |
2 | Download the latest release of the Data Optimizer from GitHub. See the Using Published Release from GitHub section for details. |
3 | Setup the optimizer database. See the Database Setup section for details. |
4 | Deploy and configure the Data Optimizer. See the Application Deployment and Configuration section for details. |
Prerequisites
Before setting-up the Data Optimizer, it is necessary to follow the MyGeotab API Adapter Solution Usage and Implementation instructions.
Using Published Release from GitHub
The latest version of the MyGeotab API Adapter solution is available on GitHub as a pre-published release for one or more target runtimes. If there is a published release version for the desired runtime, it can be downloaded per the instructions in this section. If there is no published release version for the desired runtime, it will be necessary to clone the source code repository, create a new publish profile and then follow a process similar to that outlined in the Publishing and Deployment section of the MyGeotab API Adapter - Solution and Implementation Guide to generate the release materials for deployment.
Instructions for obtaining the pre-published release of the Data Optimizer are as follows:
1 | Using a web browser, navigate to https://github.com/Geotab/mygeotab-api-adapter/releases. The latest release will be listed at the top of the page. |
2 | Files associated with the latest release are listed under the Assets heading. Self-contained deployments are packaged in zip files - the names of which are prefixed with "MyGeotabAPIAdapter.DataOptimizer_SCD_" followed by the target Runtime Identifier (e.g. "win-x64"). The SQLServer_DataOptimizer.zip file contains the scripts associated with this release. |
3 | Download the appropriate files, extract the contents and proceed with deployment. |
Database Setup
At this time, SQL Server is the only supported database type for the optimizer database. While multiple database types are supported for the adapter database, if all tables are to be included in a single physical database, it will need to be SQL Server. It is, however, possible to use different types of databases for the adapter and optimizer. For example, the adapter database could be PostgreSQL while the optimizer database is SQL Server. At some point in the future, support may be added for additional database types.
WARNING! Regardless of database type, it is possible for the database to grow very large very quickly, resulting in potential disk space and performance issues. For example, running the adapter against a MyGeotab database with a fleet of ~20,000 devices and pulling data for all supported feeds could result in an empty associated database growing to ~40 GB in size within 7 days. In such a scenario, the database might include ~225,000,000 StatusData, ~65,000,000 LogRecord and ~10,000,000 Trip records.
Please ensure that an appropriate strategy is implemented to monitor database growth and performance and take action as needed.
SQL Server
It is necessary to have access to a SQL Server (or Azure SQL) instance on which to set-up the optimizer database. Using SQL Server Management Studio, steps are as follows:
1 | Create a database named geotabadapteroptimizerdb. |
2 | Create a login named geotabadapteroptimizer_client along with a user by the same name using the following script (first replacing USE [master]; CREATE LOGIN [geotabadapteroptimizer_client] WITH
DEFAULT_DATABASE=[geotabadapteroptimizerdb], DEFAULT_LANGUAGE=[us_english], CHECK_EXPIRATION=OFF, CHECK_POLICY=OFF; USE [geotabadapteroptimizerdb]; CREATE USER [geotabadapteroptimizer_client] FOR LOGIN [geotabadapteroptimizer_client] WITH DEFAULT_SCHEMA=[dbo]; ALTER ROLE [db_datareader] ADD MEMBER [geotabadapteroptimizer_client]; ALTER ROLE [db_datawriter] ADD MEMBER [geotabadapteroptimizer_client]; |
3 | Ensure that the database collation is set to be case-sensitive by executing the following: USE [geotabadapteroptimizerdb] GO ALTER DATABASE [geotabadapteroptimizerdb] COLLATE SQL_Latin1_General_CP1_CS_AS; GO |
4 | Execute the database creation script, geotabadapteroptimizerdb-DatabaseCreationScript.sql, which can be found along with the source code in the ..\mygeotab-api-adapter\MyGeotabAPIAdapter.DataOptimizer\SQLServer folder (where mygeotab-api-adapter is the folder containing the MyGeotabAPIAdapter.sln solution file). |
5 | Executing the following: USE [geotabadapteroptimizerdb] GO GRANT EXECUTE ON [dbo].[spStatusDataTWithLagLeadLongLatBatch] TO geotabadapteroptimizer_client; |
WARNING! It is critical that the SQL Server database collation is set to case-sensitive (i.e. SQL_Latin1_General_CP1_CS_AS as noted in Step 3 above). Failure to do so will result in exceptions being encountered in situations where records are being added to tables and their GeotabId values are identical except for casing.
Application Deployment and Configuration
The next steps, after setting-up the optimizer database, are to deploy and configure the Data Optimizer application. Both of these steps are explained in this section.
✱ NOTE: The steps outlined below are for a simple scenario in which the Data Optimizer is installed on a single machine. There are other possible deployment options in which multiple instances of the optimizer can be run concurrently on different machines. See the Deployment Examples section for more information.
Because the MyGeotab API Adapter solution has been published using the Self-contained deployment mode (see this link from Microsoft for more information) in this example, it is quite simple to deploy:
1 | Copy the application folder (e.g. MyGeotabAPIAdapter.DataOptimizer_SCD_win-x64 if deploying to a Windows-based system) extracted from the zip file downloaded from GitHub in Step 2 of the Using Published Release from GitHub section to the server on which the optimizer is to reside. |
2 | Modify the appsettings.json file, contained in the above application folder, as needed. See the appsettings.json section for more information. |
3 | Review the nlog.config file, contained in the above application folder, and make any necessary changes. See the nlog.config section for more information. |
4 | Run the optimizer executable (“MyGeotabAPIAdapter.DataOptimizer” or “MyGeotabAPIAdapter.DataOptimizer.exe”, depending on the target runtime) in the published folder that was copied in Step 1. ✱ NOTE: It is best to setup a process to run the optimizer using a system account. On a Windows Server, for example, Windows Task Scheduler can be used to create a task that runs MyGeotabAPIAdapter.DataOptimizer.exe on server startup. |
Deployment Examples
Given the highly-configurable nature of the MyGeotab API Adapter solution, there are numerous possibilities when it comes to deploying the solution in a physical environment. This section outlines a few of the possible deployment options.
One Application Server and One Database
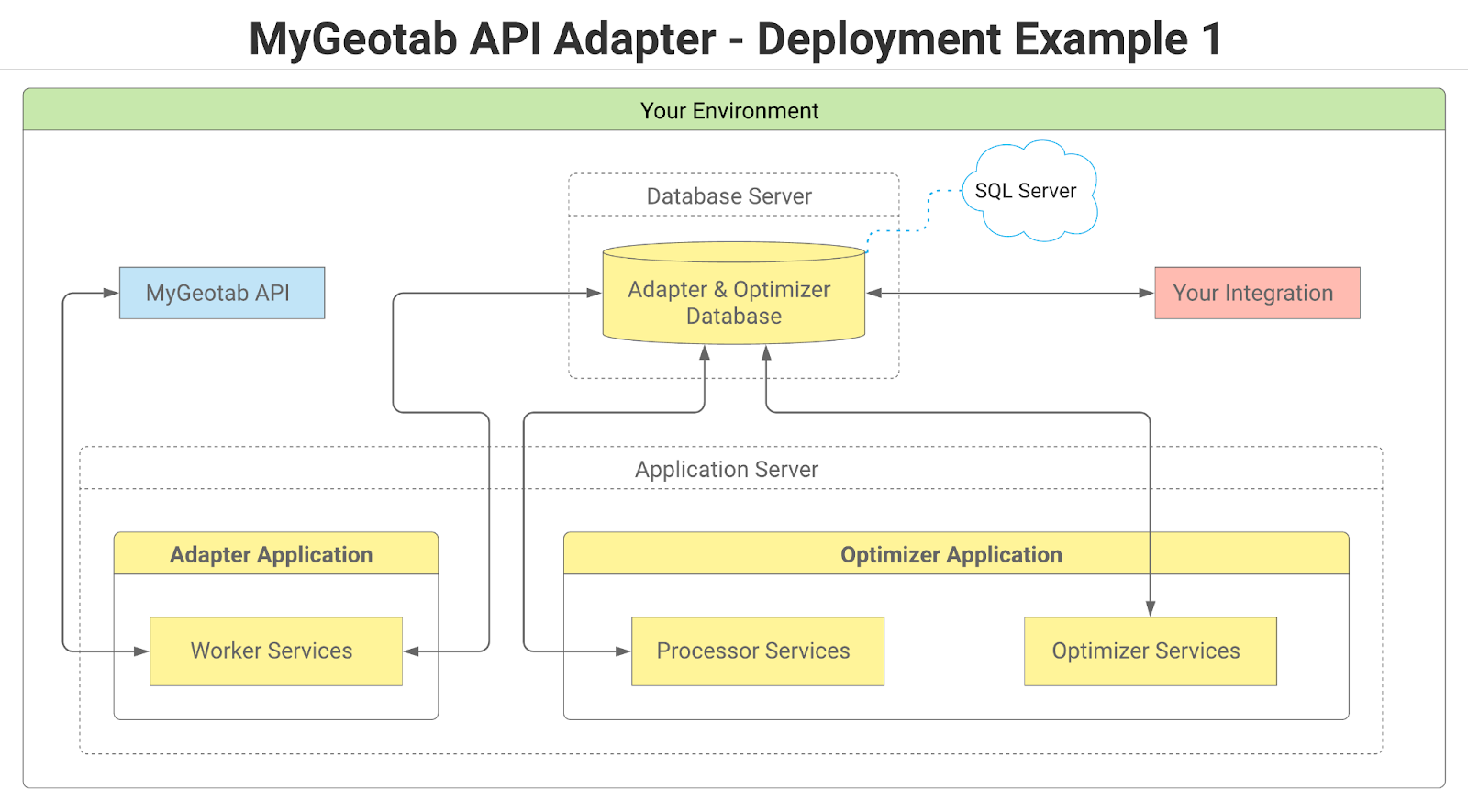
Perhaps one of the simplest deployment options, in this scenario, the adapter and optimizer applications are both installed on a single application server, while the adapter database tables and optimizer database tables are deployed to a single physical database. In this scenario, SQL Server is currently the only database option since the optimizer database only supports SQL Server.
One Application Server and Two Databases
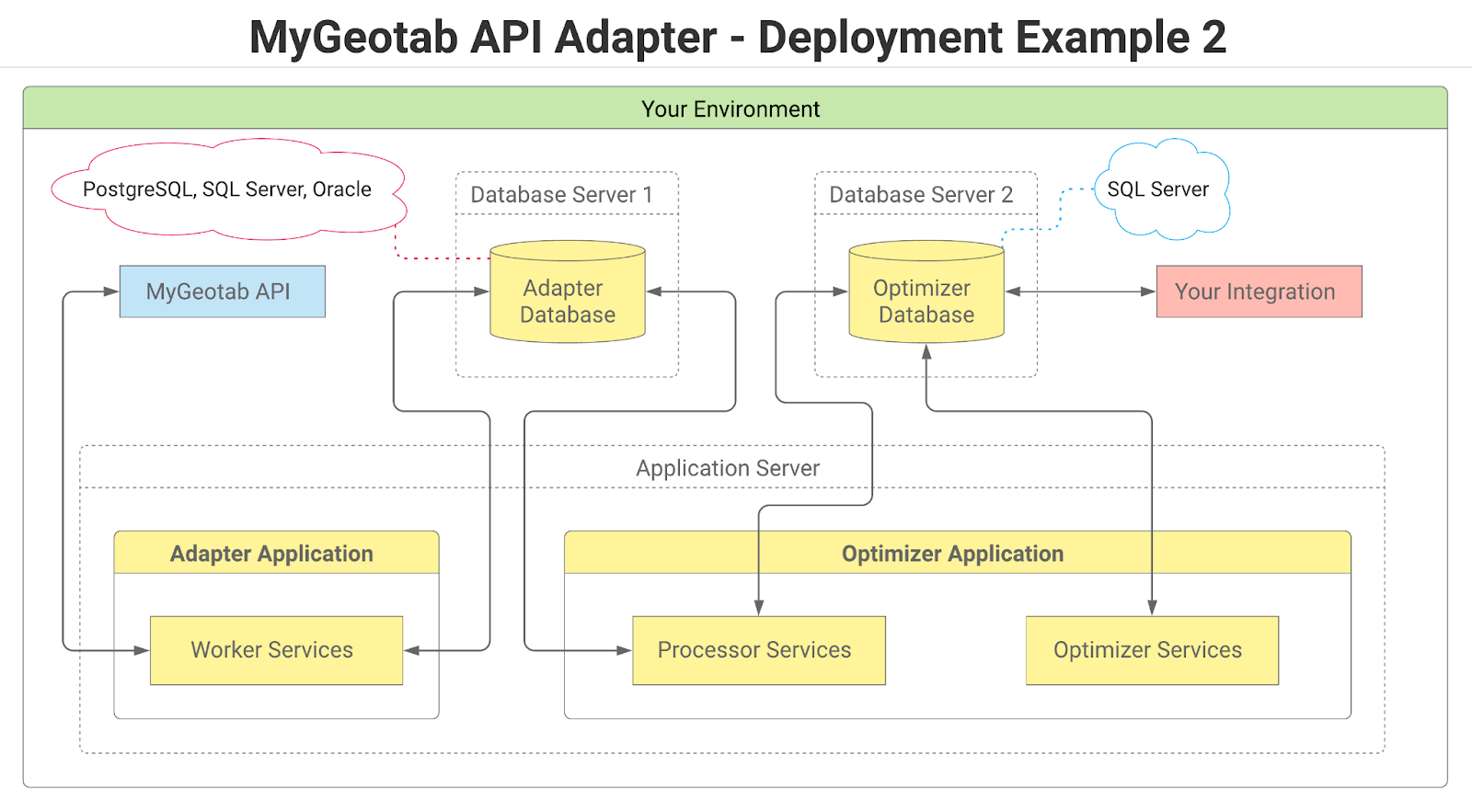
While it is technically possible to use a single physical database to host the adapter and optimizer tables, this approach is likely to prove impractical due to the number of different applications and processes simultaneously accessing the database; performance of the database and any downstream integrations will be sub-optimal. To address this concern, the adapter and optimizer tables can be separated into two physical databases, as shown in the above diagram. This is made possible by the separate adapter and optimizer database connection settings.
With the adapter database and optimizer database being two separate physical databases, the possibility of different database types is introduced. While the optimizer database can only be SQL Server (for now), the adapter database could be any one of the supported database types (i.e. PostgreSQL, SQL Server, Oracle, SQLite).
Two Application Servers and Two Databases
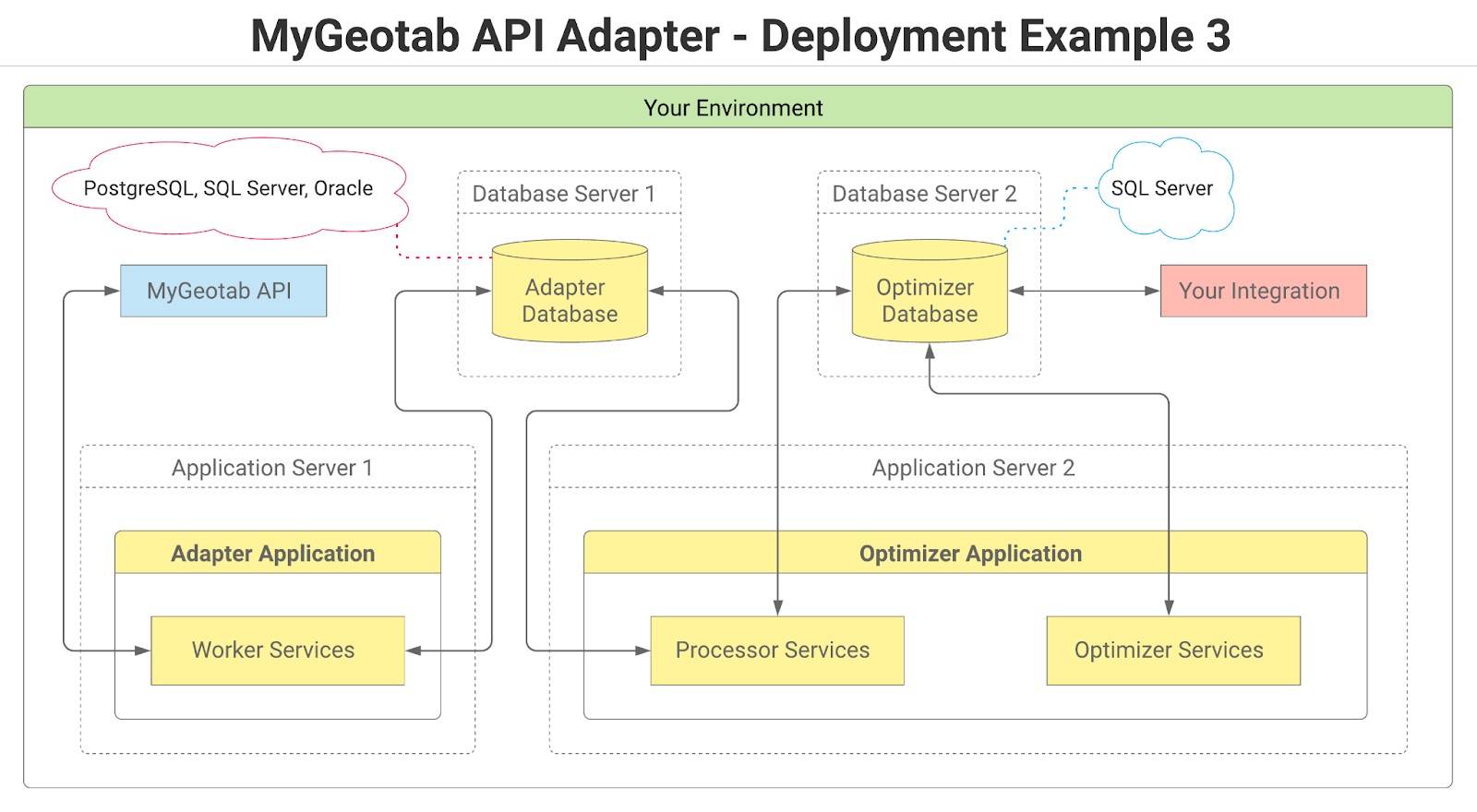
While forming part of a single overarching solution, the core MyGeotab API Adapter and the Data Optimizer are, in fact, two distinct executable applications and, given that large quantities of data are likely to be processed on a sustained basis by both applications, it may make sense to run them on two separate machines as shown in the above diagram. This type of configuration can facilitate greater performance and throughput by making more computing resources available to each application than might otherwise be available if both applications are sharing the resources of a single application server.
Three or more Application Servers and Two Databases
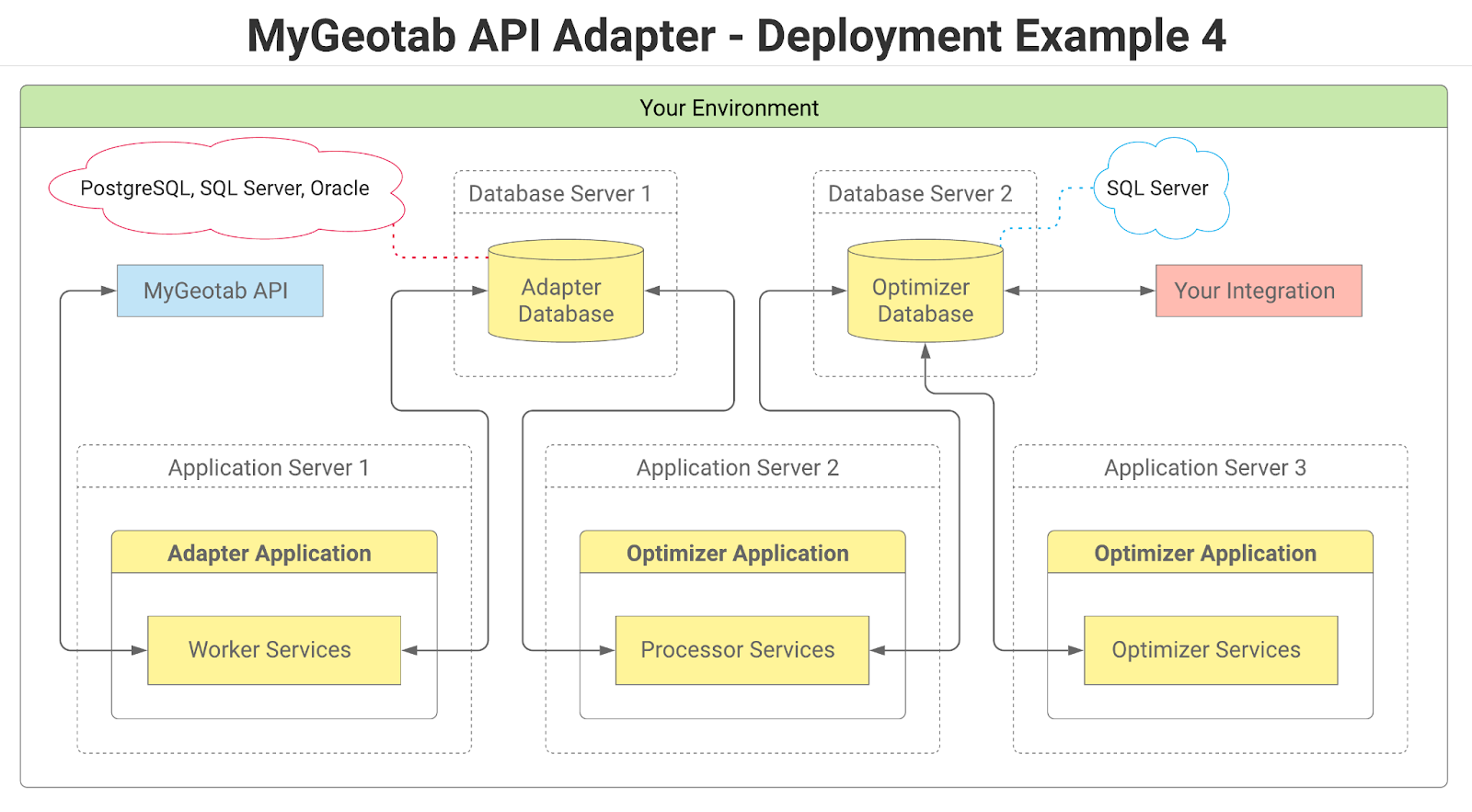
For implementations involving larger fleets, the Data Optimizer application can be distributed across a number of physical application servers to potentially achieve even greater performance and throughput. To do this, the Data Optimizer is installed on all of the desired application servers and the appsettings.json settings are then adjusted such that only certain processor or optimizer services are run on each application server. In this type of setup, it is important to ensure that:
- each processor or optimizer service is only run on one of the application servers, and
- the same version of the Data Optimizer application is installed on all of the application servers.
The optimizer includes logic that checks for the above - preventing multiple instances of a single service from being run simultaneously while also ensuring that an individual instance of the optimizer will not run if there is a newer version of the application running on one of the other servers.
! IMPORTANT: When distributing the Data Optimizer across multiple application servers, each processor or optimizer service can only be run on one of the machines. Additionally all instances of the optimizer application must be of the same version.
Understanding the Database Through Examples
This section includes information and examples to augment the rest of this guide and provide some insight into ways that data may be queried from the optimizer database to address common questions.
Using the Adapter and Optimizer Databases
✱ NOTE: At this time, the Data Optimizer is limited in scope and the optimizer database contains a limited number of tables. Additional capabilities and tables will be added incrementally over time until the optimizer database eventually includes tables to warehouse all data from the adapter database. The intention of this approach is to make capabilities available as soon as possible rather than forcing everyone to wait for an extended period for a “complete” solution to be ready.
Until the Data Optimizer has evolved to the point where all of the data from the adapter database is being propagated to the optimizer database, it will likely be necessary to use data from both databases in most cases. As a general rule, tables in the optimizer database have a “T” suffix in their names. If a table exists in both databases, then the one in the optimizer database should be used for any queries or downstream integrations. For example, the adapter database contains a LogRecords table and the optimizer database contains a corresponding LogRecordsT table. In this case, the LogRecordsT table should be used since it is optimized for usage and because the LogRecordProcessor service will delete records from the LogRecords table once they have been written to the LogRecordsT table.
In the case of Trips, the adapter database contains a Trips table, but the optimizer database does not yet contain a TripsT table. As a result, it is necessary to use the Trips table in the adapter database when looking for Trip data.
Future-Proofing Queries Against Changes to Diagnostic Ids
Occasionally, Diagnostic Ids change via the assignment of KnownIds by Geotab. While the human-readable KnownIds are more user-friendly and readily identifiable, the changing of Diagnostic Ids can present a number of challenges for integrators who may be unaware of these Id changes and who may have queries that incorporate the original Diagnostic Ids. The Data Optimizer and its associated optimizer database have been designed to future-proof queries and integrations against any negative impacts relating to changes in Diagnostic Ids.
Diagnostic GUIDs and Data Structure
Using the .NET API Client, it is possible to obtain the underlying Globally Unique Identifier (GUID) of a Diagnostic object, as shown in the following C# example:
var geotabGUID = diagnostic.Id.GetValue().ToString();
When a KnownId is assigned to an existing Diagnostic, this GUID does not change. As such, it is possible to detect changes to Diagnostic Ids and relate new Diagnostic Ids back to their previous values by using the GUID. The following diagram illustrates the table structure in relation to this particular solution (note that the FaultDataT table could be included as well, but was left out for brevity):
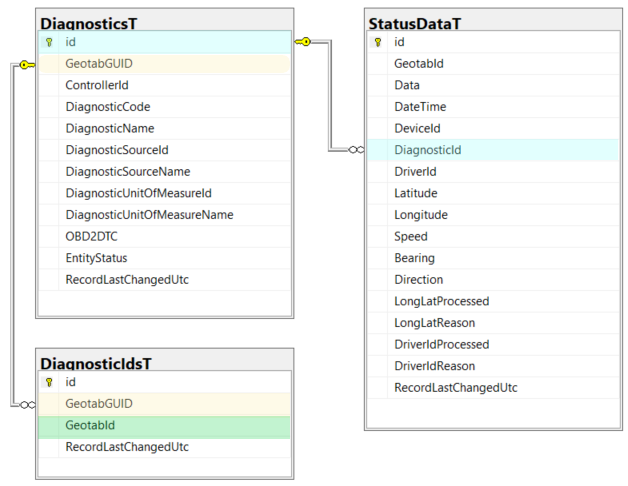
In this data structure:
- the DiagnosticsT table only contains a string representation of the underlying Diagnostic GUID (the GeotabGUID column) - not the Id which may change over time due to the assignment of a KnownId,
- the DiagnosticIdsT table contains both the Diagnostic GUID (the GeotabGUID column) and the Id (the GeotabId column), and
- the DiagnosticId column in the StatusDataT table relates back to the surrogate Id (the id column) in the DiagnosticsT table.
With this data structure and associated logic in the MyGeotab API Adapter,
- there will always be one record for a given Diagnostic in each of the DiagnosticT and DiagnosticIdsT tables, and
- an additional record will be added to the DiagnosticIdsT table each time a Diagnostic Id changes.
Using Diagnostic Ids in Queries
StatusData records are often used in queries and reports that analyze vehicle engine data. Such queries typically focus on a specific Diagnostic or set thereof and will incorporate the relevant Diagnostic Ids. When querying the StatusDataT table, with the table structure described in the previous section, it is possible to build queries that filter on specific Diagnostic Ids and be confident that those queries will still work if any of the Diagnostic Ids happen to change (due to the assignment of KnownIds).
In the following example, the StatusDataT table is queried for “Generic Adblue tank level” – a Diagnostic that originally had an Id of “aCDbCr55QuUu2GhWCSN0CkQ”. A new KnownId was assigned to the Diagnostic, which resulted in the Id changing to “DiagnosticGenericAdblueTankLevelId”. If the MyGeotab API Adapter and Data Optimizer have been running since before the KnownId was assigned to the “Generic Adblue tank level” Diagnostic, the StatusDataT table will contain data from before and after the Diagnostic Id change.
Query Created Before Diagnostic Id Change:
A query created before the KnownId was assigned would use the original Diagnostic Id:
select StatusDataT.*
from DiagnosticIdsT
inner join DiagnosticsT
on DiagnosticIdsT.GeotabGUID = DiagnosticsT.GeotabGUID
inner join StatusDataT
on DiagnosticsT.id = StatusDataT.DiagnosticId
where DiagnosticIdsT.GeotabId = N'aCDbCr55QuUu2GhWCSN0CkQ'
order by DateTime;
Query Created After Diagnostic Id Change:
A query created after the KnownId was assigned would use the new Diagnostic Id:
select StatusDataT.*
from DiagnosticIdsT
inner join DiagnosticsT
on DiagnosticIdsT.GeotabGUID = DiagnosticsT.GeotabGUID
inner join StatusDataT
on DiagnosticsT.id = StatusDataT.DiagnosticId
where DiagnosticIdsT.GeotabId = N'DiagnosticGenericAdblueTankLevelId'
order by DateTime;
As a result of the table structure and application logic of the Data Optimizer:
- Both queries will return the same result – all “Generic Adblue tank level” records in the StatusDataT table, including those that were collected when the Diagnostic Id was “aCDbCr55QuUu2GhWCSN0CkQ” and those that were collected after the Diagnostic Id changed to “DiagnosticGenericAdblueTankLevelId”.
- The changing of Diagnostic Ids will not have any impact on queries, views, reports, dashboards, applications, etc. that may have been configured to use the original Diagnostic Ids.
- Any queries specifying the new DiagnosticIds will also work for StatusData that may have been collected with the original Diagnostic Ids.
What this means in practical terms is that:
Any queries of the StatusDataT table that filter on Diagnostic Ids should be modeled on the above examples. The same applies for queries of the FaultDataT table that filter on Diagnostic Ids.
Change Log
This section tracks changes specific to the Data Optimizer portion of the MyGeotab API Adapter solution over time - by version number, in reverse chronological order. The version numbers reflect the versions of the MyGeotab API Adapter in which the subject changes to the Data Optimizer were made.
Get Notified About New Releases!
Any time a new release of the MyGeotab API Adapter is published to GitHub, an update will be posted to Geotab’s Integrator’s Hub. Click the Join Group button on the page to join and then choose the desired notification frequency (Every Post, Daily Digest, Weekly Digest, etc.)
Version 2.2.0.2
- NOTE: There are no code or database changes in this release. Updates other than those noted below are restricted to the API Adapter.
- Modified DatabaseResilienceHelper to retry on "Connection is busy" exceptions.
- Updated NuGet packages to the latest stable release.
- Updated version to 2.2.0.2.
- NOTE: There are no code or database changes in this release. Updates other than those noted below are restricted to the API Adapter.
- Updated NuGet packages to the latest stable release.
- Updated version to 2.2.0.
Version 2.2.0
Version 2.1.4
- NOTE: There are no code or database changes in this release. Updates other than those noted below are restricted to the API Adapter.
- Updated the DatabaseResilienceHelper.
- Updated all other NuGet packages to the latest stable release.
- Updated version to 2.1.4.
- NOTE: There are no database schema or configuration file changes from version 2.1.2 to version 2.1.3. It is safe to upgrade from version 2.1.2 to version 2.1.3 by simply downloading the new version and overwriting the respective appsettings.json file(s) with those that were configured for version 2.1.2.
- Updated the solution from .NET 6.0 to .NET 8.0.
- Removed ubuntu2004-x64 publish profiles due to breaking change caused by smaller RID graph in .NET 8 (see https://learn.microsoft.com/en-us/dotnet/core/compatibility/sdk/8.0/rid-graph)
- Updated all other NuGet packages to the latest stable release.
- Updated version to 2.1.3.
Version 2.1.2
- NOTE: There are no code or database changes in this release. Updates other than those noted below are restricted to the API Adapter.
- Updated all other NuGet packages to the latest stable release.
- Updated version to 2.1.2.
- NOTE: There are no code or database changes in this release. Updates other than those noted below are restricted to the API Adapter.
- Updated all other NuGet packages to the latest stable release.
- Updated version to 2.1.1.
- NOTE: There are no database schema or configuration file changes from version 2.0.10 to version 2.1.0. It is safe to upgrade from version 2.0.10 to version 2.1.0 by simply downloading the new version and overwriting the respective appsettings.json file(s) with those that were configured for version 2.0.10.
- Added Bulk Insert, Update and Delete Capabilities for PostgreSQL:
- When pairing the MyGeotab API Adapter application with a PostgreSQL database, records are now automatically inserted, updated and deleted using bulk operations. This dramatically increases throughput capability of the system. For example, whereas it may have previously taken 15-20 seconds to insert a batch of 50,000 records into the StatusData table, that same operation might now be accomplished in 1-2 seconds.
- Note: The Data Optimizer only supports SQL Server at this time.
- Updated Geotab.Checkmate.ObjectModel from version 11.0.2 to 11.0.4143.
- Updated all other NuGet packages to the latest stable release.
- Updated version to 2.1.0.
Version 2.0.10.2
- NOTE: There are no code or database changes in this release. The purpose of this update is to remove vulnerabilities in dependencies (Microsoft.NETCore.Platforms:7.0.2) by upgrading NuGet packages.
- Updated all other NuGet packages to the latest stable release.
- Updated version to 2.0.10.2.
Version 2.1.3
Version 2.1.1
Version 2.1.0
Version 2.0.10
- NOTE: This build includes changes to the API Adapter and Data Optimizer appsettings.json configuration files.
- To upgrade an existing installation of the MyGeotab API Adapter solution version 2.0.9 to version 2.0.10, see the MyGeotab API Adapter — Upgrade Guide — from v2.0.9 to v2.0.10.
- Bug fix: Modified GenericDbObjectCache interfaces/classes to use AsyncReaderWriterLock instead of SemaphoreSlim to prevent cache reads while updates are in progress. Resolves an issue whereby duplicate records may on rare occasion be inserted into “Reference Data” tables.
- Added new DisableMachineNameValidation setting for both API Adapter and Data Optimizer - to accommodate hosted deployments in environments with non-static machine names.
- Updated Geotab.Checkmate.ObjectModel from version 10.0.1 to 11.0.2.
- Updated NuGet packages to the latest stable release.
- Updated version to v2.0.10.
Version 2.0.9
- NOTE: There are no database schema or configuration file changes to the optimizer database from version 2.0.0 to version 2.0.9. It is safe to upgrade the Data Optimizer from version 2.0.0 to version 2.0.9 by simply downloading the new version and overwriting the respective appsettings.json file(s) with those that were configured for version 2.0.0.
- NOTE: This build includes changes to the schema of the adapter database and appsettings.json file. See the Change Log section in the MyGeotab API Adapter — Solution and Implementation Guide for details.
- Bug fix: Improved DB object caching logic to resolve an issue that lead to exceptions indicating duplicate items in in-memory caches.
- Added StringHelper class to assist with string comparisons potentially involving null or empty strings and modified object mapper classes to incorporate the StringHelper. This was to resolve an issue that manifested when using the API Adapter in conjunction with an Oracle database.
- Added publish profiles for the MyGeotab API Adapter and Data Optimizer applications for the ubuntu.20.04-x64 runtime.
- Updated NuGet packages to the latest stable release.
- Updated version to v2.0.9 (v2.0.6 through v2.0.8 were not published).
Version 2.0.5
- NOTE: There are no database schema or configuration file changes from version 2.0.0 to version 2.0.5. It is safe to upgrade from version 2.0.0 to version 2.0.5 by simply downloading the new version and overwriting the respective appsettings.json file(s) with those that were configured for version 2.0.0.
- Resolved issue whereby database-level rounding of sub-millisecond DateTime values resulted in equality comparison issues that further resulted in erroneous “duplicate Id” exceptions.
- Modified DatabaseResilienceHelper.CreateAsyncRetryPolicyForDatabaseTransactions method to include Exception and InnerException checks for timeout strings. Previously, command timeouts would not be caught and transactions would not be retried for timeout exceptions.
- Enhanced DatabaseResilienceHelper and MyGeotabAPIResilienceHelper to add handling for additional known exceptions as well as increasing delay between retries (with jitter) for database commands and transactions.
- Updated NuGet packages to the latest stable release.
- Updated version to v2.0.5.
Version 2.0.3
- NOTE: There are no database schema or configuration file changes from version 2.0.0 to version 2.0.3. It is safe to upgrade from version 2.0.0 to version 2.0.3 by simply downloading the new version and overwriting the respective appsettings.json file(s) with those that were configured for version 2.0.0.
- Bug fix: Resolved issue whereby introduction of new KnownIds for existing Diagnostics would cause the Data Optimizer application to crash.
- Enhanced DatabaseResilienceHelper and MyGeotabAPIResilienceHelper to add handling for additional known exception types. Also added increasing delay with a jitter of up to 1000 milliseconds between retry attempts for database commands and transactions - to avoid potential spikes in contention issues in scenarios where multiple processes are attempting to operate against the same records.
- Updated NuGet packages to the latest stable release.
- Changed version from v2.0.2 to v2.0.3.
Version 2.0.2
- NOTE: There are no database schema or configuration file changes from version 2.0.0 to version 2.0.2. It is safe to upgrade from version 2.0.0 to version 2.0.2 by simply downloading the new version and overwriting the respective appsettings.json file(s) with those that were configured for version 2.0.0.
- Bug fix: Resolved issue where duplicate values could potentially be inserted into “reference data” tables (associated with caches) causing the API Adapter and/or Data Optimizer applications to crash and become inoperable without first removing the duplicate records from the adapter database.
- Changed version from v2.0.1 to v2.0.2.
Version 2.0.1
- No logic or data model changes to Data Optimizer.
- Updated NuGet packages to the latest stable release.
- Updated version to 2.0.1.
Version 2.0.0
Version 2.0.0 of the MyGeotab API Adapter solution introduces numerous under-the-hood enhancements aimed at dramatically boosting performance, throughput and resiliency while minimizing changes to database structures and application configuration files. Changes included in this version are listed below.
Major Enhancements
Significant enhancements to the MyGeotab API Adapter solution over the previous version are listed below. Note that the changes listed in this document include only those that are relative to the Data Optimizer application.
Bulk Insert, Update and Delete Capabilities for SQL Server
When pairing the MyGeotab API Adapter and/or Data Optimizer applications with a SQL Server database (note that the Data Optimizer currently supports only SQL Server), records are now automatically inserted, updated and deleted using bulk operations. This dramatically increases throughput capability of the system. For example, whereas it may have previously taken 15-20 seconds to insert a batch of 50,000 records into the StatusData table, that same operation might now be accomplished in 1-2 seconds. When using any of the other supported database types, the traditional insert, update and delete methods are used.
Enhanced Resiliency Through Timeout and Retry Policies
With the massive amounts of data being written to databases by the API Adapter and Data Optimizer, transient exceptions may be encountered. These include things such as occasional timed-out database commands or deadlocks when multiple services attempt to operate on the same records at the same time. Additional resilience has been built into the MyGeotab API Adapter solution to handle these sorts of situations - allowing the API Adapter and Data Optimizer to continue running uninterrupted. This has been accomplished through the incorporation of Polly to provide timeout and retry capabilities for database commands and transactions.
Additional Database Indexing
Indexes have been added to tables in the adapter database to facilitate greater speed when transferring data from the adapter database to the optimizer database. Details can be found in the Additional Database Indexing notes in the MyGeotab API Adapter — Solution and Implementation Guide.
Implementation-Related Changes
This section provides information related to changes that may impact existing implementations. These include database schema changes, configuration file changes and source code changes.
Optimizer Database Schema Changes
- Modified the OProcessorTracking table:
- Added the AdapterDbLastRecordCreationTimeUtcTicks column.
- Removed the AdapterDbLastRecordCreationTimeUtc column.
Version 1.5.5
- Enhanced the solution to accommodate Diagnostic “ShimIds'' which occur when new Diagnostics with KnownIds are introduced on the MyGeotab server side, but are not yet known on the client side (as may occur when a newer version of the MyGeotab .NET API client (Geotab.Checkmate.ObjectModel NuGet package) becomes available but the current client is still using an older version). When the local NuGet package is later updated, new database records are added for the subject Diagnostics and they are related back to their former ShimId Diagnostic counterparts via the FormerShimGeotabGUID property. This allows for data captured and associated with either an old or new Diagnostic Id to be related to the single logical Diagnostic.
- Modified the DiagnosticsT table:
- Increased the length of the GeotabGUID column from 36 to 100 and changed to nvarchar.
- Added new HasShimId and FormerShimGeotabGUID columns.
- Modified the DiagnosticIdsT table:
- Increased the length of the GeotabGUID column from 36 to 100 and changed to nvarchar.
- Added new HasShimId and FormerShimGeotabGUID columns.
- Add FK relationship (FK_DiagnosticIdsT_DiagnosticsT1) to link FormerShimGeotabGUID to DiagnosticsT.GeotabGUID.
- Updated NuGet packages to the latest stable release.
- Updated version to 1.5.5.
Version 1.5.4
- Bug Fixes:
- Modified ProcessorTracker and related logic to factor-in whether a prerequisite processor has actually processed any data (vs. only checking whether it has been or is running).
- Modified processor initialization logic to factor-in scenarios in which processors are started before data exists in adapter database tables - initialization of a given service is now considered complete only once data has actually been retrieved. Resolves issues where the application could crash in various scenarios depending on timing of service execution and configuration combinations.
- Modified GenericIdCache, GenericDbObjectCache and DbDiagnosticIdTObjectCache classes to utilize their own UnitOfWorkContexts supplied via Dependency Injection - and made related changes to consuming classes. Also incorporated usage of SemaphoreSlim in initialization and update methods to make them thread safe within a singleton context. Resolves database-related exceptions that have been observed in testing.
- Modified StatusDataOptimizer and FaultDataOptimizer:
- Added independent throttling for optimization subprocesses (e.g. Longitude/Latitude interpolation subprocess and DriverId determination subprocess) to boost performance and prevent unnecessary querying of the database.
- Replaced optimizer database view vwStatusDataTWithLagLeadLongLatBatch with a stored procedure named spStatusDataTWithLagLeadLongLatBatch that uses temporary tables for better performance.
- Updated optimizer database views:
- Added indexes toStatusDataT and FaultDataT tables to boost performance of the views and stored procedure.
- Incorporated filtering to eliminate duplicates (where there are exact matches in DateTime values of StatusDataT and LogRecordT records - since a Lag and a Lead would previously be returned for each such occurrence).
- Modified views and stored procedure to include records where LeadDateTime is null - so that those records can be evaluated and updated (they are records where StatusData came in before any LogRecords for given devices) situations don’t arise where the views eventually return no records due to too many of these ones existing.
- Added comments to views and stored procedure to assist anyone seeking to replicate logic.
- Updated version to 1.5.4.
- No changes to Data Optimizer.
- Updated version to 1.5.3.
- Bug fix & Enhancement:
- Modified the InterpolateCoordinates method in LongitudeLatitudeInterpolator.cs to resolve an issue with the lagToLeadDurationTicks calculation which was resulting in incorrect placement of interpolated StatusData and FaultData coordinates.
- Updated the following views in the optimizer database (found the the geotabadapteroptimizerdb-DatabaseCreationScript.sql script) to add result sorting and remove duplicate records in cases where StatusData or FaultData record DateTime values are exact matches to LogRecord DateTime values:
- vwFaultDataTWithLagLeadDriverChangeBatch
- vwFaultDataTWithLagLeadLongLatBatch
- vwStatusDataTWithLagLeadDriverChangeBatch
- vwStatusDataTWithLagLeadLongLatBatch
- Updated all NuGet packages to the latest stable release.
- Updated version to 1.5.2.
Version 1.5.1
- Enhanced the solution to provide handling for changes to Diagnostic Ids:
- Modified the DiagnosticsT table:
- Removed the GeotabId column.
- Added a new GeotabGUID column.
- Added the DiagnosticIdsT table.
- Added the related Future-Proofing Queries Against Changes to Diagnostic Ids section to this guide.
- Added the Understanding the Database Through Examples section to this guide.
- Added “MultipleActiveResultSets=True” to SQL Server connection strings in appsettings.json to facilitate querying the optimizer database while processor and/or optimizer services are running.
- Migrated solution from .NET 5.0 to .NET 6.0.
- Updated all NuGet packages to the latest stable release.
- Added “TrustServerCertificate=True” to SQL Server connection strings in appsettings.json to remedy a connection issue arising after the migration to .NET 6.0.
- Updated version to 1.5.1.
- Introduced the Data Optimizer into the MyGeotab API Adapter solution.
Version 1.5.3
Version 1.5.2
Version 1.5.0.0



